The General Data Protection Regulation (GDPR) was introduced by the European Union to address growing concerns about privacy and data protection in a world increasingly dominated by technology. The implementation of these regulations has revolutionized the way businesses collect, process, and store data. But what exactly do these changes mean for companies operating in Europe? And what are the consequences of not adhering to them?
Portuguese Hospital Fined by CNPD
In 2018, the Comissão Nacional de Protecção de Dados (CNPD) fined Barreiro-Montijo Hospital 400,000 euros. This Portuguese authority oversees personal data protection. The incident is a major example of GDPR enforcement in the European Union.
The Barreiro-Montijo Hospital Center in Portugal faced penalties for numerous and grave violations. An inspection revealed that the hospital lacked internal regulations for creating accounts and managing access to medical data. Moreover, there was a failure in taking steps to remove accounts of employees who had left the hospital. Additionally, patient data access was mishandled, leading to breaches.
Permission Management: How to Avoid Similar Issues?
Modern institutions, particularly those in the medical sector, must give special attention to permission management. Adequately structured and consistently implemented procedures in this field can not only shield institutions from potential sanctions but also elevate the overall level of information security.

Introducing a clear security policy is the cornerstone. It meticulously dictates who can access information and how much. Yet, that’s just the beginning.
These procedures should encompass not only the granting and revoking of permissions but also their regular reviews and updates. As the organizational structure changes and the roles of employees shift, permissions should be readjusted to continually reflect actual needs and maintain optimal security levels.
Moreover, it’s prudent to introduce systems monitoring access and user activities. Such systems not only bolster security by detecting unauthorized access but also act as audit tools, potentially providing evidence in the event of violations.
In conclusion, training staff on security policies and permission management is vital. Even the most robust system can falter if employees lack awareness of their roles and responsibilities in data protection.
Conclusion
The penalty given to Barreiro-Montijo Hospital in Portugal is a warning. It highlights the importance of permission management. It also emphasizes the consequences of GDPR violations. Safeguarding personal data has multiple purposes. It’s not just about avoiding fiscal penalties. It’s mainly about building trust with customers and patients. Institutions hold many people’s data. In today’s era, data protection is essential. It’s not a luxury.
Welcome to Wizards! We are specialists in data protection, providing effective tools for detecting, anonymizing, and retaining personal data. Our services ensure full compliance with GDPR in terms of personal data protection.
We have 25 years of experience in creating systems for handling sensitive data across various sectors. We utilize cutting-edge technologies such as big data and machine learning. As committed developers and co-owners of the company, we understand the challenges related to GDPR compliance. We want to relieve other specialists from these challenges. This allows them to focus on their own tasks.
f you are looking for tools to manage personal and sensitive data, please contact us. Let’s schedule a conversation. It’s the first step to ensure your company can avoid potential fines. Contact us today.
Understand the Consequences of Violating GDPR
Understand the Consequences of Violating GDPR: Non-compliance with Rules such as Improper Data Retention or Incorrect Anonymization Can Lead to Administrative Sanctions and Financial Penalties.
In accordance with Article 83(5) of the GDPR, violations of the provisions concerning general principles, such as retention or minimization, may result in the imposition of a monetary penalty of up to 20,000,000 EUR or, for enterprises, up to 4% of the total global annual turnover of the previous fiscal year. In the case of both amounts, the higher one applies.
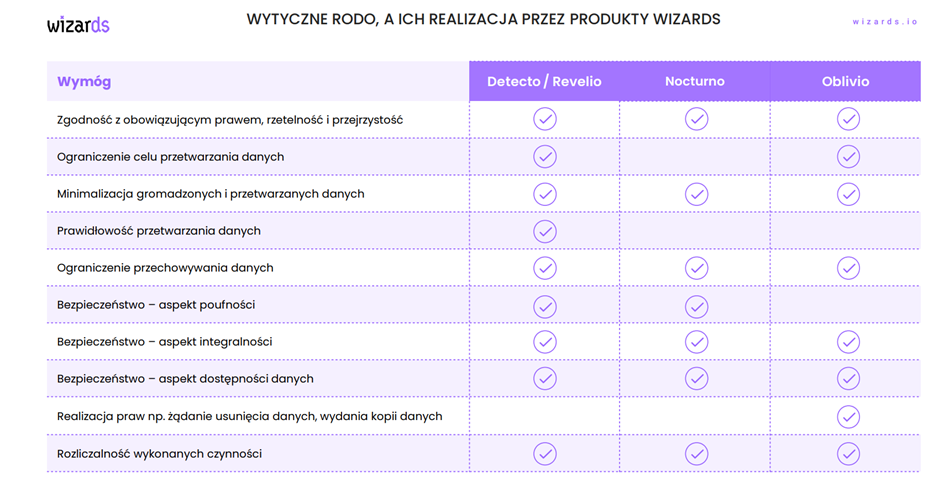
The key aspects of data processing are multifaceted. They include compliance with the law, fairness, and transparency. Purpose limitation and data minimization are also vital. Additionally, accuracy and security are crucial, encompassing aspects such as confidentiality, integrity, and availability. It is also essential to consider the rights, such as deletion or copying of data, and the responsibility for processing.
Check our tools
By choosing Wizards, you protect your company from potentially massive costs arising from GDPR violations. This can be illustrated by the example of British Airways, which was fined 204 million euros for personal data breaches in 2019. Through our collaboration, you can be assured of the safety of your finances, business, employees, and customers.
- Detecto, a system that monitors personal and sensitive data in databases, supporting anonymization and retention processes.
- Revelio, an effective solution for identifying personal and sensitive data in documents and email, promoting the digitization of business processes.
- Nocturno, an advanced system for anonymizing personal data in IT systems, maintaining data consistency between different systems.
- Oblivio, a dedicated system for managing personal data retention within an organization.
With Wizards, you’ll ensure GDPR compliance, protect your company from costly penalties associated with regulation breaches, and safeguard not only your finances but also your business, employees, and customers.

Practical Application of Our Tools
Our tools have real-world applications that translate into the daily functioning of companies. Below, we present specific examples.
Detecto. A telecommunications company was using an advanced ERP solution from one of the leading providers. During an audit, IT had to locate places within the ERP system where personal data were stored. Detecto from Wizards scanned the system’s databases and provided a report with the locations of personal and financial data.
Revelio. In an insurance company, despite using various security tools, there was a leak of customer data and financial information. Revelio helped identify over 1000 files containing more than 100 customer names along with bank account numbers, gathered in the SharePoint repository and on personal computers.
Nocturno. A client was using 20 different IT systems. To handle this complexity, Wizards Nocturno automated the process of creating test and development environments. During this creation, the system ensured that personal and sensitive data were anonymized. Moreover, this anonymization did not affect the qualitative and quantitative parameters of the data. As a result, it allowed for secure testing and software development.
Oblivio. A public institution was processing the data of its employees. Oblivio helped identify which data should be deleted in accordance with data retention regulations. The tool also took care of the anonymization of employee data that needed to be removed from the human resources systems.
Would you like to learn more about the practical applications of our tools? Contact us for a conversation. We have dozens of other examples!
Collaboration Models
Secure your business with one move. Discover our collaboration options and schedule a conversation to safeguard your enterprise.
Collaboration Options:
- Detecto – Identification of personal data in three selected databases for 10,000 PLN.
- Revelio – Identification of personal data in shared resource files (up to 100,000 files) for 10,000 PLN.
- Oblivio – Information on the quantity of personal data subject to retention, stored in your database (applies to 1 process, max 3 systems) for 10,000 PLN.
We offer one-time use options or subscriptions for a period of a month or a year.
With us, it’s worth it!
RODO regulations can be difficult to understand and implement. At Wizards, we focus on accessibility and effectiveness. Our tools, Detecto, Revelio, Nocturno, and Oblivio, tailored to your needs, provide efficient personal data management and full compliance with GDPR.
Don’t let the fear of GDPR hinder your company’s growth. With us, you gain confidence and security, enabling you to focus on what’s most important – your business. So choose Wizards, choose the only proper protection. Then schedule a conversation with us today and safeguard your company from the consequences of GDPR violations.
Processing personal data is an integral part of the digital reality. Companies face many challenges. Cybercrime poses a serious threat. Society is becoming more aware of its privacy. Legal regulations, including GDPR, set specific requirements. Companies need to approach them flexibly and responsibly. However, it’s hard to determine the impact of these elements on the development of artificial intelligence (AI).
Cybercrime
Cybercrime is a significant challenge in today’s world. The intensity of this problem is increasing every year. In business language, terms such as hacking attacks, phishing, and ransomware have become common. Companies processing personal data must invest in IT security systems. They also need to train their teams. This allows them to effectively counter threats. Data security is a priority for every business.
Social awareness of privacy
The right to privacy is a basic human right. In the era of digitization, it becomes even more important. Customers are increasingly aware of their rights. They expect companies to be transparent in data processing. Companies that do not meet these expectations risk losing customers’ trust. This, in turn, can lead to a loss of their loyalty.
The right to privacy is a basic human right. It enables control over information about oneself. It protects against improper use. GDPR, as a European regulation, crucially treats this right.
GDPR obliges companies to protect the processed data, and companies must inform individuals about the purposes of processing their data. They also must allow them access to these data.
GDPR introduces the right to be forgotten, which means that an individual can request the deletion of their data in certain situations. Additionally, the right to data portability is another element of GDPR that allows data to be transferred between service providers.
So, the right to privacy in the context of GDPR is control over personal data. It’s protection against their improper processing.
Increasing legal requirements
GDPR is a key regulation regarding data processing. It introduces many requirements that companies must meet. Severe sanctions threaten violations of these regulations. They can reach up to 20 million euros. Alternatively, it can be 4% of the company’s global turnover. This demonstrates the seriousness of the right to privacy in the European Union. Companies, therefore, need to dedicate resources to ensure GDPR compliance. This is also necessary for other legal provisions.

GDPR and artificial intelligence
Artificial intelligence is an area of progress and innovation. However, it must comply with GDPR regulations. Companies are obligated to inform customers about the processing of their data by algorithms. They also need to provide a “right to explanation” for automatic decisions. Such requirements can slow down the development of AI. At the same time, they can encourage the creation of more “transparent” and ethical AI models.
Solutions and the future
Challenges in data processing are significant, but surmountable. New technologies can increase privacy and data security. Companies investing in advanced AI must integrate GDPR principles at the design stage. This is known as privacy by design. Training employees and building a culture of respect for privacy is key. This applies to all levels of the organization.
Conclusion
Data has become the new “gold” in our world. The ability to manage it is the key to success. GDPR may pose a challenge, but it also offers an opportunity to build trust. Increasing customer loyalty is possible thanks to this. We observe dynamic development of technology, including artificial intelligence. An approach to data that combines innovation and ethics will be the key to future success. What do you think, who will win the battle, GDPR or artificial intelligence?

It would be hard to miss all the articles on the topic of GDPR and all the various, terrifying sanctions that could be put upon an entity for non-compliance. Few, however, delve into important details, such as the significance of anonymization or data retention, which allow for avoiding all these sanctions and make the work of developers significantly easier. For this reason, we decided to explain in an accessible way what anonymization and retention of personal data are and show why their proper implementation is of such importance in the software development process. Today, let us tackle anonymization.
What is anonymization?
Anonymization is a process that allows you to permanently remove the link between personal data and the person to whom the data relates. Thanks to this, what was previously deemed as personal ceases to be that.
What does it look like in practice?
The definition above becomes less complicated when presented with an example. Let us imagine, for example, Superman – a comic hero from Krypton who wants to hide his identity and blend in with the crowd.
| Name | Superman |
| Occupation | Superhero |
| Origin | Krypton |
During the anonymization process, Superman enters the telephone booth, puts on glasses and a tweed suit, and becomes Clark Kent, a reporter from Kansas.
| Name | Clark Kent |
| Occupation | Reporter |
| Origin | Kansas, USA |
Through the anonymization process, Superman’s data turned into Clark Kent’s, and there is no connection between these two people. This is fictitious data that can be safely used, e.g. in test environments.
The example above illustrates the process of anonymization itself. Let us now consider why it is important that the anonymization is of good quality.
Irreversibility
The foundation of anonymization is its irreversibility. We should never be able to find out what the original data looked like, based on the anonymized data. Clark’s associates should not be able to discover his true identity.
When we anonymize a data set, usually only a fragment of the data will undergo change. However, we must ensure that non-anonymized data does not allow the anonymization process to be reversed for the entire set. In our example, we would not have to change Superman’s favorite color. However, if we do not anonymize his origin, we would certainly cause a sensation.
True to reality
An important qualitative measure of anonymization is also how well it imitates reality. If Superman and all other people in the data set are anonymized as follows:
| Name | X |
| Occupation | Y |
| Origin | Z |
we have no doubt that the process is irreversible, but its usefulness is questionable. Person X does not look like someone who exists in reality, and the nature of the original data has not been preserved. The length of the names were not preserved, and the data itself looks unbelievable with all of the people having the same name. In the case of IT systems, the tester using such data would run into a lot of issues, he would not even be able to distinguish between people.
Repeatability
Another feature of good anonymization is its repeatability. When anonymizing the data set, we want to make sure that each time the data set would be anonymized in the same way. We want Superman to always become Clark Kent, no matter whether it’s the first or the tenth anonymization. This is especially important from the point of view of Quality Assurance. Testers often create test cases based on specific data. If this data were changed every time, the tester’s work would certainly be more difficult!
Integrated systems
Today’s IT world is represented by countless systems connected with each other. Hardly any application can function as a single organism. Systems connect with each other, exchanging data and using each other’s services. Therefore, when approaching anonymization, we must consider the process not only for one system, but for many systems at once. The challenge is for anonymized data to be consistent throughout the entire ecosystem. This means that if the Daily Planet (Clark’s workplace) has a human resources system and a blog, then in both applications Superman will become Clark Kent.
Efficiency
The last key parameter affecting the quality of anonymization, from my point of view, is performance. IT systems process huge data sets measured in gigabytes or even terabytes. Anonymization of such databases can be time consuming, therefore, we must ensure not only security but also good speed of the anonymization process. One of the things Superman learned after arriving on Earth is that time is money. This saying rings even more true in the case of modern IT.
I invite everyone interested in the topic of data retention to read my next article, which I plan on publishing shortly.
Artur Żórawski, Founder & CTO