Ochronie Danych Osobowych (RODO) zostało wprowadzone przez Unię Europejską jako odpowiedź na rosnące obawy związane z prywatnością i ochroną danych w świecie coraz bardziej zdominowanym przez technologię. Wprowadzenie tych regulacji spowodowało rewolucję w sposobie, w jaki przedsiębiorstwa zbierają, przetwarzają i przechowują dane. Jednak co dokładnie oznaczają te zmiany dla firm działających w Europie? I jakie są konsekwencje ich nieprzestrzegania RODO w szpitalach?
Portugalski Szpital ukarany przez CNPD
W 2018 roku, Comissão Nacional de Protecção de Dados (CNPD), portugalski organ nadzorczy w dziedzinie ochrony danych osobowych, nałożył na Centrum Szpitalne Barreiro-Montijo grzywnę w wysokości 400 tysięcy euro. To zdarzenie stanowi znaczący przykład egzekwowania przepisów RODO w szpitalach w Unii Europejskiej.
Centrum Szpitalne Barreiro-Montijo w Portugalii zostało ukarane za liczne i poważne naruszenia. Kontrola wykazała, że szpital nie miał wewnętrznych regulacji dotyczących tworzenia kont i zarządzania dostępem do danych medycznych. Ponadto, nie podjęto kroków, aby usunąć konta pracowników, którzy zakończyli pracę w szpitalu. Dodatkowo, dostęp do danych pacjentów był niewłaściwie zarządzany, co spowodowało naruszenia.
Zarządzanie uprawnieniami: Jak unikać podobnych problemów?
Współczesne instytucje, zwłaszcza te działające w sektorze medycznym, muszą zwracać szczególną uwagę na zarządzanie uprawnieniami. Odpowiednio skonstruowane i konsekwentnie wdrażane procedury w tej dziedzinie mogą nie tylko uchronić placówki przed niepotrzebnymi sankcjami, ale również poprawić ogólny poziom bezpieczeństwa informacji.
Kluczem jest jasna polityka bezpieczeństwa. Musi ona dokładnie regulować dostępy. Kto ma dostęp i jak długo? Ale to tylko początek. Procedury muszą być pełne. Nadawanie i odbieranie uprawnień są ważne. Regularne przeglądy i aktualizacje są kluczowe.

Struktura organizacyjna ewoluuje. Zakres obowiązków pracowników zmienia się. Uprawnienia muszą być dostosowywane. Powinny odzwierciedlać rzeczywiste potrzeby. Zapewniają one optymalny poziom bezpieczeństwa.
Dodatkowo, warto wdrażać systemy monitorowania. Śledzą one dostęp i aktywność użytkowników. Te systemy zwiększają bezpieczeństwo. Wykrywają nieautoryzowany dostęp. Służą też jako narzędzie audytu. Mogą dostarczyć dowodów przy naruszeniach.
Ostatecznie, szkolenie pracowników w zakresie polityki bezpieczeństwa i zarządzania uprawnieniami jest niezbędne. Nawet najlepszy system może zawieść, jeśli pracownicy nie są świadomi swoich obowiązków i odpowiedzialności w zakresie ochrony danych.
Podsumowanie
Centrum Szpitalne Barreiro-Montijo w Portugalii otrzymało karę. Stanowi to przestrogę dla wszystkich instytucji. Podkreśla to znaczenie zarządzania uprawnieniami. Świadomość konsekwencji naruszenia RODO w szpitalach jest kluczowa. Troska o dane osobowe to więcej niż unikanie sankcji. Chodzi też o budowanie zaufania. Zaufanie jest ważne w relacjach z klientami i pacjentami. Instytucje przechowują dane wielu osób.
Witaj w Wizards! Jesteśmy specjalistami od ochrony danych, dostarczając skuteczne narzędzia do wykrywania, anonimizacji i retencji danych osobowych. Nasze usługi zapewniają pełną zgodność z RODO w zakresie ochrony danych osobowych.
Posiadamy 25-letnie doświadczenie w tworzeniu systemów do obsługi wrażliwych danych w różnych sektorach, wykorzystując najnowsze technologie, takie jak big data i uczenie maszynowe. Jako zaangażowani programiści i współwłaściciele firmy, chcemy odciążyć innych specjalistów od wyzwań związanych z przestrzeganiem RODO. Umożliwiając im tym samym skupienie się na ich własnych zadaniach.
Jeżeli poszukujesz narzędzi do zarządzania danymi osobowymi i wrażliwymi, zapraszamy do kontaktu. Umówmy się na rozmowę. To pierwszy krok, aby Twoja firma mogła uniknąć potencjalnych kar. Skontaktuj się z nami już dziś!
Poznaj konsekwencje z naruszania RODO
Nieprzestrzeganie zasad RODO, takich jak niewłaściwe ograniczenie przechowywania danych (retencji) czy niewłaściwa anonimizacja, prowadząc do naruszenia poufności, może prowadzić do sankcji administracyjnych i nałożenia kar finansowych.
Zgodnie z art. 83 ust. 5 RODO, naruszenia przepisów dotyczących kwestii związanych z zasadami ogólnymi, takimi jak retencja czy minimalizacja, mogą skutkować nałożeniem kary pieniężnej do 20 000 000 EUR, a dla przedsiębiorstw – do 4% całkowitego rocznego światowego obrotu z poprzedniego roku obrotowego. W przypadku obu kwot, zastosowanie znajduje ta wyższa.
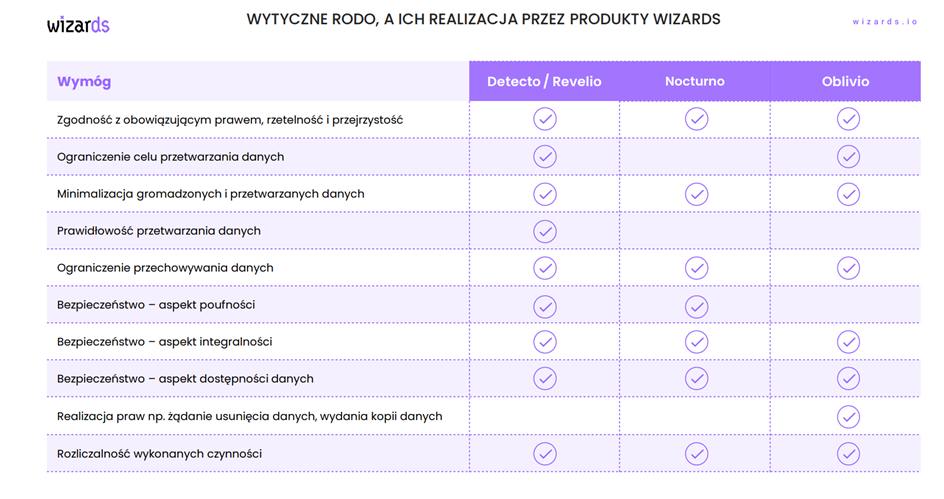
Kluczowe aspekty przetwarzania danych to: zgodność z prawem, rzetelność, przejrzystość, ograniczenie celu i minimalizacja danych, ich prawidłowość i bezpieczeństwo, w tym poufność, integralność i dostępność. Niezbędne jest także uwzględnienie praw, jak usuwanie czy kopiowanie danych, oraz odpowiedzialność za przetwarzanie.
Sprawdź nasze narzędzia
Wybierając Wizards, chronisz swoją firmę przed potencjalnie ogromnymi kosztami wynikającymi z naruszenia przepisów RODO. Można to zobrazować na przykładzie British Airways, które w 2019 roku zostało ukarane karą w wysokości 204 mln euro za naruszenie danych osobowych. Dzięki naszej współpracy, możesz być pewien bezpieczeństwa swoich finansów, przedsiębiorstwa, pracowników i klientów.
- Detecto, system monitorujący dane osobowe i wrażliwe w bazach danych, wspierający procesy anonimizacji i retencji.
- Revelio, skuteczne rozwiązanie do identyfikacji danych osobowych i wrażliwych w dokumentach oraz poczcie elektronicznej, promujące cyfryzację procesów biznesowych.
- Nocturno, zaawansowany system do anonimizacji danych osobowych w systemach informatycznych, zachowujący spójność danych między różnymi systemami.
- Oblivio, dedykowany system do zarządzania retencją danych osobowych w organizacji.
Z Wizards, zapewnisz zgodność z RODO, ochronisz swoją firmę przed kosztownymi karami związanymi z naruszeniem przepisów i zabezpieczysz nie tylko swoje finanse, ale także firmę, pracowników i klientów.
Praktyczne zastosowanie naszych narzędzi
Nasze narzędzia mają realne zastosowanie, które przekłada się na codzienne funkcjonowanie firm. Przedstawiamy poniżej konkretne przykłady.
Detecto. Firma z sektora telekomunikacji korzystała z zaawansowanego rozwiązania klasy ERP jednego z czołowych dostawców. Podczas audytu, IT musiało zlokalizować miejsca w systemie ERP, w którym przechowywane są dane osobowe. Detecto z Wizards przeskanowało bazy danych systemu i dostarczyło raport z lokalizacjami danych osobowych i finansowych.
Revelio. W firmie ubezpieczeniowej, mimo zastosowania różnych narzędzi bezpieczeństwa, doszło do wycieku danych klientów i informacji finansowych. Revelio pomogło zidentyfikować ponad 1000 plików zawierających ponad 100 nazwisk klientów wraz z numerami kont bankowych, zgromadzonych w repozytorium SharePoint i na komputerach osobistych.
Nocturno. Klient korzystał z 20 różnych systemów informatycznych. Dlatego Wizards Nocturno zautomatyzował proces tworzenia środowisk testowych i developerskich, tak, że podczas tworzenia, dane osobowe i wrażliwe były anonimizowane. Co więcej, anonimizacja nie zmienia parametrów jakościowych i ilościowych danych, co pozwoliło na bezpieczne testowanie i rozwój oprogramowania.
Oblivio. Instytucja publiczna przetwarzała dane swoich pracowników. Oblivio pomogło zidentyfikować, które dane powinny być usunięte zgodnie z przepisami o retencji danych. Narzędzie zadbało również o anonimizację danych pracowników, które powinny być usunięte z systemów kadrowych.
Chcesz dowiedzieć się więcej o praktycznym zastosowaniu naszych narzędzi? Skontaktuj się z nami na rozmowę. Mamy dziesiątki innych przykładów!
Modele współpracy
Zabezpiecz swoją firmę jednym ruchem. Odkryj nasze opcje współpracy i umów rozmowę, aby zabezpieczyć swoje przedsiębiorstwo.
Opcje Współpracy:
- Detecto – Identyfikacja danych osobowych w trzech wybranych bazach danych za 10 000 PLN.
- Revelio – Identyfikacja danych osobowych w plikach zasobu współdzielonego (do 100 000 plików) za 10 000 PLN.
- Oblivio – Informacja o ilości danych osobowych, które podlegają retencji, przechowywanych w Twojej bazie (dotyczy 1 procesu, max 3 systemy) za 10 000 PLN.
Oferujemy opcje jednorazowego użytku lub subskrypcji na okres miesiąca lub roku.

Z nami warto!
Przepisy RODO mogą być trudne do zrozumienia i zastosowania. W Wizards, stawiamy na przystępność i skuteczność. Nasze narzędzia Detecto, Revelio, Nocturno i Oblivio, dostosowane do Twoich potrzeb, zapewniają efektywne zarządzanie danymi osobowymi i pełną zgodność z RODO.
Nie pozwól na hamowanie rozwoju Twojej firmy przez strach przed RODO. Dlatego też z nami zyskujesz pewność i bezpieczeństwo, co umożliwia Ci skupienie się na tym, co najważniejsze – Twoim biznesie. Tak więc wybierz Wizards, wybierz jedyną słuszną ochronę. Następnie umów się na rozmowę z nami już dziś i zabezpiecz swoją firmę przed konsekwencjami naruszenia RODO.
RODO to skrót od Rozporządzenia Ogólnego o Ochronie Danych Osobowych, czyli unijnego aktu prawnego, który reguluje ochronę prywatności i przetwarzanie danych osobowych w Europie. Wprowadzono to rozporządzenie 25 maja 2018 roku, które zastąpiło poprzednią dyrektywę o ochronie danych osobowych.
RODO nakłada na firmy i organizacje obowiązek przestrzegania szeregu przepisów dotyczących przetwarzania danych osobowych, w tym zbierania, przetwarzania, przechowywania i usuwania tych informacji. Celem RODO jest zapewnienie ochrony prywatności i uniknięcie nadużyć w stosunku do danych osobowych.
Naruszenie tych przepisów może skutkować poważnymi sankcjami nie tylko reputacyjnymi ale i drakońskimi karami finansowymi. Warto również pamiętać, że każda firma lub organizacja, która przetwarza dane osobowe w Unii Europejskiej musi przestrzegać RODO.
Jaki szereg przepisów nakłada RODO na firmy?
RODO wymaga od firm i organizacji, które przetwarzają dane osobowe, aby poinformowały zainteresowane osoby o celach przetwarzania tych danych oraz o prawach jakie im przysługują. Osoby te mają również prawo dostępu do swoich danych oraz prawo do ich poprawiania, usuwania i przenoszenia. RODO nakłada na firmy i organizacje szereg przepisów, których przestrzeganie jest obowiązkowe.
- Zasada przejrzystości – firmy i organizacje muszą informować osoby, których dane dotyczą, o celach przetwarzania ich danych jak i o tym, kto jest administratorem ich danych,
- Zasada ograniczenia celu – dane osobowe powinny być zbierane i przetwarzane tylko wtedy, gdy jest to niezbędne do realizacji określonych celów,
- Zasada minimalizacji danych – firmy i organizacje powinny zbierać i przetwarzać tylko te dane osobowe, które są niezbędne do realizacji określonych celów,
- Zasada poprawności danych – firmy i organizacje muszą dbać o to, aby dane osobowe były aktualne i poprawne,
- Zasada ograniczenia przechowywania danych – dane osobowe nie powinny być przechowywane dłużej niż jest to niezbędne,
- Zasada poufności i bezpieczeństwa – firmy i organizacje muszą chronić dane osobowe przed nieautoryzowanym dostępem, utratą lub uszkodzeniem.
Firma musi również prowadzić dokładną dokumentację dotyczącą przetwarzania danych osobowych. W tym rejestry czynności przetwarzania oraz ewidencję naruszeń ochrony danych osobowych. Dodatkowo, musi wyznaczyć Inspektora Ochrony Danych (IOD). Odpowiedzialny on będzie za monitorowanie przestrzegania zasad ochrony danych osobowych i kontakt z organem nadzorczym.

Jakie są kary za złamanie RODO?
RODO przewiduje wysokie kary finansowe za naruszenie przepisów. Wysokość kar zależy od rodzaju naruszenia i okoliczności sprawy. Można ukarać firmę lub organizację za m.in.:
- naruszenie zasad przetwarzania danych osobowych. Kara może wynosić do 20 milionów euro lub 4% globalnego rocznego obrotu firmy (w zależności od tego, która kwota jest wyższa);
- naruszenie obowiązków dotyczących powiadamiania o naruszeniu ochrony danych osobowych. Kara może wynosić do 10 milionów euro lub 2% globalnego rocznego obrotu firmy (w zależności od tego, która kwota jest wyższa);
- naruszenie praw osób, których dane dotyczą. Kara może wynosić do 20 milionów euro lub 4% globalnego rocznego obrotu firmy (w zależności od tego, która kwota jest wyższa).
Największe kary nałożone za złamanie RODO
W 2019 roku francuski organ nadzorczy nałożył na Google karę w wysokości 50 milionów euro za naruszenie zasad RODO. Firma nie dostarczała wystarczających informacji na temat sposobu przetwarzania danych oraz nie uzyskiwała odpowiedniego zgody na przetwarzanie danych osobowych użytkowników.
W 2020 roku brytyjski organ nadzorczy nałożył na British Airways karę w wysokości 183 milionów funtów za naruszenie RODO. Firma nie zabezpieczyła odpowiednio swojej strony internetowej, co umożliwiło cyberatak i wyciek danych osobowych klientów.
W 2021 roku niemiecki organ nadzorczy nałożył na H&M karę w wysokości 35,3 milionów euro za naruszenie prywatności pracowników. Firma zbierała i przetwarzała nielegalnie dane osobowe swoich pracowników w celu monitorowania ich życia prywatnego i życia rodzinnego.
Sprawdź nasze produkty i ochroń swoją firmę
Wdrażając Nocturo, Oblivio i Detecto – zwiększysz bezpieczeństwo wrażliwych danych w swojej organizacji oraz zgodność RODO.
Detecto: Narzędzie do wykrywania danych osobowych oraz wrażliwych w bazach danych,
Nocturno: Narzędzie do anonimizacji danych osobowych w systemach informatycznych,
Oblivio: System do retencji danych osobowych i zarządzania danymi osobowymi w organizacji.
Skontaktuj się z nami, a zabezpieczymy Twoją firmę przed niepożądanymI karami finansowymi. Nasze produkty spełniają wszystkie zasady nakładane przez RODO.
Co muszę zrobić, aby moja firma przestrzegała przepisów RODO?
Aby wdrożyć przepisy RODO w firmie, musisz przede wszystkim:
- Określić cele przetwarzania danych osobowych: musisz określić, w jaki sposób będziesz przetwarzał dane osobowe i jakie cele będą tym kierować.
- Zidentyfikować podstawę prawą przetwarzania danych osobowych: musisz określić, jakie przepisy prawa umożliwiają przetwarzanie danych osobowych w Twojej firmie.
- Przygotować politykę prywatności i informować o niej klientów: musisz przygotować politykę prywatności. Która określa, jakie dane są zbierane, w jaki sposób są przetwarzane. Kto jest odpowiedzialny za ich przetwarzanie, jakie są prawa klientów związane z ich danymi osobowymi, itp. Następnie musisz upewnić się, że klienci są informowani o polityce prywatności przed udostępnieniem swoich danych osobowych.
- Zapewnić bezpieczeństwo przetwarzania danych osobowych: musisz zabezpieczyć dane osobowe przed utratą, zniszczeniem lub nieuprawnionym dostępem. Musisz wykorzystać odpowiednie środki techniczne i organizacyjne, takie jak szyfrowanie, regularne tworzenie kopii zapasowych, autoryzacja dostępu, itp.
- Wdrożyć procedury przetwarzania danych osobowych: musisz wprowadzić procedury przetwarzania danych osobowych, które będą przestrzegać przepisów RODO. Określić, jakie kroki należy podjąć w przypadku naruszenia ochrony danych osobowych.
- Szkolić pracowników: musisz przeszkolić pracowników na temat przepisów RODO i wdrożonych procedur przetwarzania danych osobowych.
Pamiętaj, że przestrzeganie przepisów RODO to proces ciągły i wymaga stałego monitorowania i aktualizacji procedur.

Mało kogo ominęły przepastne artykuły na temat RODO i przeróżnych, często przerażających sankcji za jej nieprzestrzeganie. Niewielu za to zagłębia się w takie istotne szczegóły, jak znacznie anonimizacji czy retencji, które pozwalają uniknąć tych wyżej wspomnianych sankcji oraz znacząco ułatwić pracę deweloperów. Z tego też względu postanowiliśmy w przystępny sposób wyjaśnić, czym są anonimizacja i retencja danych osobowych oraz pokazać, dlaczego ich właściwe wykonanie ma takie znaczenie w procesie wytwarzania oprogramowania. Dzisiaj na warsztat bierzemy anonimizację.
Czym jest anonimizacja?
Anonimizacja to proces pozwalający na trwałe usunięcie powiązań między danymi osobowymi, a osobą, której dotyczą. W ten sposób informacje, które przed anonimizacją były danymi osobowymi, przestają nimi być.
Jak to wygląda w praktyce?
Powyższa definicja staje się mniej zagmatwana jeśli wesprzemy ją przykładem. Wyobraźmy sobie np. Supermana – komiksowego bohatera pochodzącego z Kryptonu, który chce ukryć swoją tożsamość i wtopić się w tłum.
| Nazwa | Superman |
| Zawód | Bohater |
| Pochodzenie | Krypton |
Podczas procesu anonimizacji Superman wchodzi do budki telefonicznej, zakłada okulary, tweedowy garnitur i staje się w tym momencie Clarkiem Kentem, reporterem z Kansas.
| Nazwa | Clark Kent |
| Zawód | Reporter |
| Pochodzenie | Kansas, USA |
W procesie anonimizacji dane Supermana zamieniły się na dane Clarka Kenta, co więcej nie ma żadnego powiązania między tymi dwiema osobami. To dane fikcyjne, które mogą być bezpiecznie wykorzystywane np. na środowiskach testowych.
Powyższy przykład obrazuje, na czym polega sam proces anonimizacji. Zastanówmy się teraz, dlaczego ważne jest, żeby anonimizacja była dobrej jakości.
Nieodwracalność
Fundamentem anonimizacji jest jej nieodwracalność. Na podstawie zanonimizowanych danych nigdy nie powinniśmy dociec, jak wyglądały dane oryginalne. Współpracownicy Clarka nie powinni odkryć jego prawdziwej tożsamości.
Kiedy zbiór danych poddajemy anonimizacji, to zazwyczaj zmianie ulega jedynie fragment danych. Musimy jednak zadbać o to, aby dane niezanonimizowane nie pozwoliły na odwrócenie procesu anonimizacji dla całego zbioru. W naszym przykładzie nie musielibyśmy zmieniać ulubionego koloru Supermana. Jeżeli jednak nie anonimizujemy jego pochodzenia, to z pewnością wzbudzimy sensację.
Realność
Istotną miarą jakościową anonimizacji jest też jej realność i to, jak dobrze odwzorowuje rzeczywistość. Jeżeli Superman i wszystkie inne osoby w zbiorze danych zostaną zanonimizowane w następujący sposób:
| Nazwa | X |
| Zawód | Y |
| Pochodzenie | Z |
to nie mamy wątpliwości, że proces jest nieodwracalny, jednak jego przydatność jest wątpliwa. Pan X nie wygląda na człowieka z krwi i kości, a charakter danych oryginalnych nie został zachowany. Długości nazw nie zostały zachowane, a same dane wyglądają na niewiarygodne i wszystkie osoby nazywają się tak samo. W przypadku systemów informatycznych tester wykorzystując takie dane miałby sporo problemów, nie byłby w stanie nawet rozróżnić osób.
Powtarzalność
Kolejną cechą dobrej anonimizacji jest jej powtarzalność. Anonimizując zbiór danych chcemy mieć pewność, że za każdym razem zbiór danych zostanie zanonimizowany w taki sam sposób. Chcemy, aby Superman zawsze stawał się Clarkiem Kentem, niezależnie czy jest to pierwsza, czy dziesiąta anonimizacja. Jest to szczególnie ważne z punktu widzenia Quality Assurance. Testerzy często tworzą przypadki testowe opierając się na konkretnych danych. Gdybyśmy je zmieniali za każdym razem, z pewnością praca testera byłaby trudniejsza!
Zintegrowane systemy
Dzisiejszy świat informatyki to systemy połączone. Prawie żadna aplikacja nie jest samotną wyspą. Systemy łączą się ze sobą, wymieniają danymi, korzystają ze swoich usług. Z tego też względu podchodząc do anonimizacji, musimy myśleć o procesie nie dla jednego, ale dla wielu systemów na raz. Wyzwaniem jest, aby zanonimizowane dane były spójne w całym ekosystemie. Oznacza to, że jeżeli Daily Planet (miejsce pracy Clarka) posiada system kadrowy oraz bloga, to w obu tych aplikacjach Superman stanie się Kentem.
Wydajność
Ostatnim z mojego punktu widzenia, kluczowym parametrem mającym wpływ na jakość anonimizacji jest wydajność. Systemy informatyczne przetwarzają olbrzymie zbiory danych liczonych w gigabajtach czy terabajtach. Anonimizacja takich baz danych może być czasochłonna w związku z czym musimy zapewnić nie tylko bezpieczeństwo, ale również szybkość procesu anonimizacji. Jedną z rzeczy, którą nauczył się Superman po przybyciu na Ziemię, jest to, że czas to pieniądz. To powiedzenie jest jeszcze bardziej prawdziwe w przypadku nowoczesnego IT.
Wszystkich zainteresowanych tematem retencji danych zapraszam do przeczytania kolejnego mojego artykułu, który planuję opublikować już niedługo.
Artur Żórawski, Founder&CTO Wizards