W obliczu rosnących zagrożeń cybernetycznych, ochrona danych osobowych stała się priorytetem dla firm na całym świecie. Skuteczne zarządzanie danymi wymaga zastosowania nowoczesnych strategii i narzędzi. Omówmy praktyczne podejścia do ochrony danych w erze cyfrowej.
Audyt i inwentaryzacja danych
Aby skutecznie zarządzać danymi, firmy przeprowadzają szczegółowy audyt i inwentaryzację. Muszą wiedzieć, jakie dane posiadają, gdzie są przechowywane i kto ma do nich dostęp. Nasze produkty, Detecto i Revelio, skanują i analizują bazy danych oraz różne zasoby, pomagając identyfikować potencjalne luki w zabezpieczeniach i minimalizować ryzyko naruszenia danych.
Szyfrowanie danych
Szyfrowanie danych stanowi jeden z najskuteczniejszych sposobów ochrony informacji. Firmy powinny szyfrować dane zarówno w tranzycie, jak i w spoczynku, co zapobiega nieautoryzowanemu dostępowi. Nowoczesne algorytmy szyfrowania sprawiają, że nawet przechwycone dane pozostają nieczytelne dla osób trzecich.
Zarządzanie dostępem i tożsamością
Kontrolowanie dostępu do danych jest kluczowe dla ich ochrony. Firmy wdrażają zasady najmniejszych uprawnień, co oznacza, że pracownicy mają dostęp tylko do danych niezbędnych do wykonywania ich obowiązków. Zastosowanie uwierzytelniania wieloskładnikowego (MFA) zwiększa poziom bezpieczeństwa. Ponadto, anonimizacja danych na środowiskach testowych i developerskich oraz zarządzanie retencją i prawem do zapomnienia ogranicza dostęp do danych.

Regularne aktualizacje i łatki bezpieczeństwa
Firmy muszą regularnie aktualizować oprogramowanie używane do przechowywania i przetwarzania danych, aby chronić przed najnowszymi zagrożeniami. Śledzą nowe luki bezpieczeństwa i natychmiast wdrażają dostępne łatki.
Szkolenia pracowników
Dobrze przeszkoleni pracownicy są niezastąpionym elementem ochrony danych. Firmy regularnie szkolą swoje zespoły w zakresie najlepszych praktyk w ochronie danych. Pracownicy są świadomi zagrożeń, takich jak phishing, i wiedzą, jak na nie reagować.
Używanie narzędzi do monitorowania i wykrywania zagrożeń
Narzędzia do monitorowania sieci i wykrywania zagrożeń szybko identyfikują i reagują na podejrzane aktywności. Systemy te wykorzystują zaawansowane algorytmy i sztuczną inteligencję do analizowania ruchu sieciowego i identyfikowania potencjalnych zagrożeń w czasie rzeczywistym.
Wnioski
Ochrona danych osobowych w erze cyfrowej wymaga kompleksowego podejścia, które łączy technologię, procedury i edukację pracowników. Inwestując w regularne audyty, szyfrowanie danych, zarządzanie dostępem, aktualizacje oprogramowania, szkolenia i zaawansowane narzędzia do monitorowania, firmy nie tylko zabezpieczają swoje dane, ale także budują zaufanie klientów i przestrzegają regulacji prawnych.
W maju 2018 roku wprowadzenie Regulacji Ogólnego Rozporządzenia o Ochronie Danych (RODO) zainicjowało przełomowy moment dla ochrony danych osobowych w Unii Europejskiej. RODO nie tylko zrewolucjonizowało sposób, w jaki dane osobowe są chronione na terenie UE, ale także wywarło znaczący wpływ na firmy na całym świecie, promując jednolity standard ochrony danych wśród wszystkich państw członkowskich.
Od rozdrobnienia do spójności
Przed RODO, różnorodność przepisów o ochronie danych między krajami UE stanowiła wyzwanie dla przedsiębiorstw międzynarodowych, generując niepewność prawną i stawiając bariery dla działalności transgranicznej. RODO wprowadziło jednolite zasady, umożliwiając firmom łatwiejsze zarządzanie danymi osobowymi i zapewniając obywatelom UE wyższy poziom ochrony prywatności.
Wzmocnienie praw obywateli i transparentność działania
RODO wzmocniło prawa osób, których dane dotyczą, wprowadzając takie mechanizmy jak prawo do bycia zapomnianym, prawo dostępu do danych, czy prawo do sprostowania. Te inicjatywy zwiększyły kontrolę jednostek nad ich danymi osobowymi, promując większą transparentność w działaniach organizacji.
Wpływ globalny RODO
RODO wpłynęło znacząco nie tylko na przedsiębiorstwa działające wewnątrz Unii Europejskiej, ale także na te poza jej granicami. Firmy spoza UE, przetwarzające dane obywateli UE w celach oferowania towarów lub usług, czy monitorowania ich zachowań, również muszą przestrzegać RODO. To globalne zasięganie sprawia, że RODO staje się de facto międzynarodowym standardem ochrony danych.
Wprowadzenie RODO zainspirowało wiele krajów do przeglądu i ulepszenia własnych przepisów dotyczących ochrony danych. Na przykład, ustawa o prywatności konsumentów w Kalifornii (CCPA) oraz ogólna ustawa o ochronie danych w Brazylii (LGPD) czerpią z doświadczeń RODO, dążąc do podniesienia standardów ochrony danych na własnym terytorium. RODO stało się globalnym punktem odniesienia dla regulacji ochrony danych, promując wysokie standardy ochrony danych osobowych na całym świecie.
Przedsiębiorstwa w obliczu nowych wyzwań
Implementacja RODO wymagała od przedsiębiorstw międzynarodowych dostosowania polityk i procedur ochrony danych, co dla wielu z nich było wyzwaniem. Jednakże, te początkowe inwestycje w zgodność z RODO przyniosą długoterminowe korzyści, zwiększając zaufanie konsumentów i promując bezpieczniejsze środowisko cyfrowe.
Przyszłość RODO
RODO nie tylko zjednoczyło rynek cyfrowy w UE, ale również podniosło poprzeczkę dla ochrony danych osobowych na świecie. Jako żywy dokument, RODO prawdopodobnie będzie ewoluować, aby sprostać nowym wyzwaniom technologicznym i społecznym, nadal inspirując globalne podejście do prywatności i ochrony danych.

Inspirujący globalne standardy
Zapoczątkowanie przez RODO globalnej dyskusji na temat ochrony danych osobowych ujawniło potrzebę międzynarodowej współpracy w tej dziedzinie. Wymiana najlepszych praktyk i współpraca regulacyjna między krajami i regionami staje się coraz ważniejsza w miarę, jak cyfrowa gospodarka przekracza granice. RODO, jako model do naśladowania, pokazuje, że wysoki poziom ochrony danych osobowych i praw jednostki może iść w parze z innowacjami i rozwojem gospodarczym.
Dalsze wyzwania i możliwości
Mimo mocnych fundamentów RODO, przed nami wiele wyzwań. Technologie takie jak AI, uczenie maszynowe, i IoT stawiają nowe pytania. Chodzi o prywatność i ochronę danych. W odpowiedzi, instytucje UE i organy nadzorcze muszą dostosowywać interpretacje. Także wytyczne muszą być aktualizowane. To wszystko, aby RODO spełniało cele w zmieniającym się świecie technologii.
Edukacja i świadomość
Kluczem do długoterminowego sukcesu RODO jest edukacja i podnoszenie świadomości zarówno wśród przedsiębiorstw, jak i obywateli. Rozumienie praw i obowiązków jest niezbędne do budowania kultury ochrony danych, w której prywatność jest traktowana jako podstawowe prawo, a nie jako opcja. Organizacje, które traktują ochronę danych jako integralną część swojej strategii biznesowej, zyskują konkurencyjną przewagę, budując zaufanie i lojalność klientów.
Podsumowanie
RODO stało się kamieniem milowym w ochronie danych osobowych. Ustanowiło silne, jednolite ramy dla Europy. Inspiruje zmiany na całym świecie. Jego wpływ na globalne przedsiębiorstwa jest znaczący. Dotyczy także regulacji w innych krajach i rozwoju technologicznego. Podkreśla to znaczenie adaptacyjnej postawy wobec ochrony danych. Proaktywna postawa jest również kluczowa. Wchodzimy teraz w nową erę cyfrową. Przyszłość RODO nadal odgrywa kluczową rolę. Kształtuje przyszłość ochrony prywatności i danych osobowych. Ale działa na poziomie globalnym. Wyznacza standardy dla innych krajów i regionów. Te kraje i regiony będą dążyć do spełnienia tych standardów.
Współczesny świat dynamicznie rozwija się w kierunku cyfryzacji różnych aspektów naszego życia. Nie tylko media, edukacja czy zakupy przenoszą się do przestrzeni wirtualnej, ale również oficjalne dokumenty. Jednym z flagowych przykładów tego trendu jest aplikacja mObywatel, której popularność w Polsce rośnie z roku na rok. Jakie funkcje oferuje mObywatel? Co aplikacja o nas wie? Jakie nowe regulacje wprowadza najnowsza ustawa? Oto kompleksowy przewodnik po świecie mObywatel.
Czym jest mObywatel?
mObywatel to innowacyjna aplikacja mobilna stworzona przez polski rząd, która umożliwia przechowywanie i korzystanie z elektronicznych wersji oficjalnych dokumentów, takich jak dowód osobisty, legitymacja szkolna czy studencka. Narzędzie to ułatwia życie milionom Polaków, eliminując potrzebę noszenia ze sobą tradycyjnych wersji tych dokumentów.
Bezpieczeństwo przede wszystkim
Bezpieczeństwo danych osobowych jest priorytetem dla twórców aplikacji. Przetwarzanie danych w mObywatel odbywa się z pełnym poszanowaniem prywatności użytkowników. Informacje takie jak imię, nazwisko, numer PESEL czy zdjęcie użytkownika pochodzą z oficjalnych rejestrów państwowych, gwarantując ich autentyczność. Co ważne, te dane są zabezpieczane za pomocą zaawansowanych technologii szyfrowania, co minimalizuje ryzyko ich nieautoryzowanego dostępu. Kluczowym elementem bezpieczeństwa jest również wymóg podania osobistego kodu PIN przed dostępem do aplikacji.
Bogate możliwości aplikacji
mObywatel nie jest tylko elektronicznym dowodem osobistym. Aplikacja pozwala na:
- Potwierdzanie tożsamości za pomocą smartfona w różnych instytucjach i punktach obsługi klienta.
- Załatwianie różnorodnych spraw urzędowych online.
- Sprawdzanie swoich punktów karnych oraz uprawnień kierowcy.
- Elektroniczne potwierdzanie szczepień, w tym przeciwko COVID-19.
- Okazywanie mLegitymacji szkolnej i studenckiej.
- I wiele innych funkcji, które ułatwiają codzienne życie obywateli.
Najnowsza ustawa a mObywatel
Ostatnie zmiany w przepisach prawnych jeszcze bardziej poszerzyły zakres uprawnień i funkcjonalności aplikacji mObywatel. Nowa ustawa, która weszła w życie, dopuszcza korzystanie z mObywatel w szerszym zakresie instytucji i urzędów, uczyniła też aplikację bardziej funkcjonalną i dostosowaną do potrzeb użytkowników. Warto śledzić regularne aktualizacje, aby być na bieżąco z nowościami i możliwościami, jakie oferuje aplikacja.

mObywatel w kontekście międzynarodowym
Gdy przyglądamy się rozwiązaniom z innych krajów, widzimy, że trend cyfryzacji usług publicznych jest globalny. Estonia, na przykład, jest często uważana za pioniera w tej dziedzinie dzięki swojemu programowi e-Residency i e-ID. Obywatele Estonii korzystają z elektronicznych kart identyfikacyjnych, które oferują szeroki zakres usług online, od prowadzenia działalności gospodarczej po głosowanie w wyborach.
W Azji, Singapur zaimponował swoim systemem SingPass, który pozwala mieszkańcom na łatwy dostęp do usług rządowych, takich jak wnioskowanie o benefity czy przeglądanie wyników medycznych. Szwecja z kolei rozwijała system BankID, który stał się standardem weryfikacji tożsamości online w wielu sytuacjach, zarówno w usługach komercyjnych, jak i publicznych.
Jednak nie wszystkie systemy były przyjęte bez kontrowersji. System Aadhaar w Indiach, mimo że znacznie uproszcza procesy biurokratyczne dla prawie 1,3 miliarda obywateli, budził pewne obawy związane z prywatnością i bezpieczeństwem danych.
W kontekście tych międzynarodowych inicjatyw, mObywatel stanowi wyważone połączenie funkcji identyfikacyjnych z szerokim zakresem usług. Jest odpowiedzią Polski na globalny trend cyfryzacji, oferując Polakom nowoczesne narzędzie dostosowane do lokalnych potrzeb i standardów.
Podsumowanie
W dobie rosnącej cyfryzacji mObywatel to narzędzie, które znacznie upraszcza codzienne czynności i ułatwia kontakt z instytucjami państwowymi. Dzięki wysokiemu poziomowi bezpieczeństwa oraz ciągłym aktualizacjom staje się niezbędnym elementem smartfona każdego Polaka. Korzystając z niej, stajemy się aktywnymi uczestnikami cyfrowego świata, w którym tradycyjne metody ustępują miejsca nowoczesnym rozwiązaniom.
Regulacja Ogólna o Ochronie Danych (RODO) od czasu swojego wejścia w życie w 2018 roku stała się jednym z głównych tematów debat dotyczących ochrony prywatności. Wokół RODO narosło wiele mitów i nieporozumień. Poznaj 10 mitów RODO!
RODO dotyczy tylko dużych firm
Nieprawda! RODO dotyczy każdej organizacji lub osoby fizycznej, która przetwarza dane osobowe mieszkańców Unii Europejskiej, niezależnie od wielkości firmy czy rodzaju działalności.
Uchybienia w RODO zawsze skutkują ogromnymi grzywnami
Choć możliwe są wysokie kary finansowe za nieprzestrzeganie RODO, w rzeczywistości organy nadzorcze dążą do tego, aby najpierw edukować i pomagać firmom w dostosowaniu się do przepisów.
Dane osobowe to tylko imię i nazwisko
Błąd! Dane osobowe to wszelkie informacje, które można przypisać do konkretnej osoby. Dotyczy to także adresu e-mail, numeru telefonu, lokalizacji czy danych związanych z aktywnością w internecie.
Zawsze potrzebna jest zgoda na przetwarzanie danych
Nie zawsze. Istnieją różne podstawy prawne do przetwarzania danych, w tym wykonanie umowy czy prawnie uzasadniony interes administratora.
Dane można przechowywać w nieskończoność
Nieprawda. Zgodnie z RODO, dane osobowe powinny być przechowywane tylko tyle czasu, ile jest to konieczne do celów, w jakich zostały zebrane.

RODO dotyczy tylko firm z siedzibą w UE
Zastosowanie RODO ma do każdej firmy, która oferuje towary lub usługi mieszkańcom UE, niezależnie od miejsca jej siedziby.
RODO zabrania przechowywania kopii zapasowych danych
To nieprawda. Kopie zapasowe są ważne dla bezpieczeństwa danych, ale należy je odpowiednio zabezpieczyć i przestrzegać zasad RODO podczas ich przechowywania.
Jeśli firma korzysta z usług podmiotu trzeciego do przetwarzania danych, to nie jest odpowiedzialna za ewentualne naruszenia
Błędne założenie. Firma zlecająca przetwarzanie danych nadal ponosi odpowiedzialność za ich bezpieczeństwo.
RODO dotyczy wyłącznie danych elektronicznych
Nie tylko. RODO dotyczy danych przetwarzanych zarówno w formie elektronicznej, jak i papierowej.
Każde naruszenie RODO trzeba zgłosić odpowiednim organom
Nie każde. Zgłoszenie jest wymagane tylko w przypadku naruszeń, które mogą prowadzić do “wysokiego ryzyka dla praw i wolności osób fizycznych”.
Podsumowując, RODO wprowadziło wiele ważnych zmian w zakresie ochrony danych osobowych. Aby prawidłowo przestrzegać przepisów, warto poznać fakty i oddzielić je od mitów krążących wokół tej regulacji.
Ochronie Danych Osobowych (RODO) zostało wprowadzone przez Unię Europejską jako odpowiedź na rosnące obawy związane z prywatnością i ochroną danych w świecie coraz bardziej zdominowanym przez technologię. Wprowadzenie tych regulacji spowodowało rewolucję w sposobie, w jaki przedsiębiorstwa zbierają, przetwarzają i przechowują dane. Jednak co dokładnie oznaczają te zmiany dla firm działających w Europie? I jakie są konsekwencje ich nieprzestrzegania RODO w szpitalach?
Portugalski Szpital ukarany przez CNPD
W 2018 roku, Comissão Nacional de Protecção de Dados (CNPD), portugalski organ nadzorczy w dziedzinie ochrony danych osobowych, nałożył na Centrum Szpitalne Barreiro-Montijo grzywnę w wysokości 400 tysięcy euro. To zdarzenie stanowi znaczący przykład egzekwowania przepisów RODO w szpitalach w Unii Europejskiej.
Centrum Szpitalne Barreiro-Montijo w Portugalii zostało ukarane za liczne i poważne naruszenia. Kontrola wykazała, że szpital nie miał wewnętrznych regulacji dotyczących tworzenia kont i zarządzania dostępem do danych medycznych. Ponadto, nie podjęto kroków, aby usunąć konta pracowników, którzy zakończyli pracę w szpitalu. Dodatkowo, dostęp do danych pacjentów był niewłaściwie zarządzany, co spowodowało naruszenia.
Zarządzanie uprawnieniami: Jak unikać podobnych problemów?
Współczesne instytucje, zwłaszcza te działające w sektorze medycznym, muszą zwracać szczególną uwagę na zarządzanie uprawnieniami. Odpowiednio skonstruowane i konsekwentnie wdrażane procedury w tej dziedzinie mogą nie tylko uchronić placówki przed niepotrzebnymi sankcjami, ale również poprawić ogólny poziom bezpieczeństwa informacji.
Kluczem jest jasna polityka bezpieczeństwa. Musi ona dokładnie regulować dostępy. Kto ma dostęp i jak długo? Ale to tylko początek. Procedury muszą być pełne. Nadawanie i odbieranie uprawnień są ważne. Regularne przeglądy i aktualizacje są kluczowe.

Struktura organizacyjna ewoluuje. Zakres obowiązków pracowników zmienia się. Uprawnienia muszą być dostosowywane. Powinny odzwierciedlać rzeczywiste potrzeby. Zapewniają one optymalny poziom bezpieczeństwa.
Dodatkowo, warto wdrażać systemy monitorowania. Śledzą one dostęp i aktywność użytkowników. Te systemy zwiększają bezpieczeństwo. Wykrywają nieautoryzowany dostęp. Służą też jako narzędzie audytu. Mogą dostarczyć dowodów przy naruszeniach.
Ostatecznie, szkolenie pracowników w zakresie polityki bezpieczeństwa i zarządzania uprawnieniami jest niezbędne. Nawet najlepszy system może zawieść, jeśli pracownicy nie są świadomi swoich obowiązków i odpowiedzialności w zakresie ochrony danych.
Podsumowanie
Centrum Szpitalne Barreiro-Montijo w Portugalii otrzymało karę. Stanowi to przestrogę dla wszystkich instytucji. Podkreśla to znaczenie zarządzania uprawnieniami. Świadomość konsekwencji naruszenia RODO w szpitalach jest kluczowa. Troska o dane osobowe to więcej niż unikanie sankcji. Chodzi też o budowanie zaufania. Zaufanie jest ważne w relacjach z klientami i pacjentami. Instytucje przechowują dane wielu osób.
Regulacje dotyczące prywatności danych, takie jak RODO (Rozporządzenie o ochronie danych osobowych), są kluczowym aspektem prowadzenia działalności gospodarczej w dzisiejszych czasach. Zarówno dużym firmom, jak i małym przedsiębiorstwom, zależy na ochronie prywatności swoich klientów i zgodności z prawem. Sprawdź błędy RODO.
Jednym z najważniejszych aspektów tych regulacji jest retencja danych osobowych, czyli praktyka przechowywania danych klientów przez określony czas. W tym artykule omówimy, jakie błędy firmy najczęściej popełniają w tej dziedzinie i jak ich uniknąć.
Podstawowe informacje o RODO i retencji danych
RODO, w pełni znane jako Ogólne Rozporządzenie o Ochronie Danych, jest regulacją Unii Europejskiej, która wprowadza surowe zasady dotyczące sposobu, w jaki firmy mogą zbierać, przechowywać i przetwarzać dane osobowe. Zasady te obejmują prawo osób do dostępu do swoich danych, prawo do poprawiania błędów w swoich danych i prawo do bycia zapomnianym, co oznacza, że firmy muszą usunąć dane klientów na ich żądanie.
Retencja danych odnosi się do praktyki przechowywania danych klientów przez określony czas. Okres retencji danych może być różny dla różnych typów danych i zależy od wielu czynników, takich jak przepisy prawne, zasady firmy i potrzeby biznesowe. Ważne jest, aby firmy miały jasno zdefiniowane i dobrze zarządzane procesy retencji danych, aby zapewnić zgodność z RODO i innymi regulacjami dotyczącymi prywatności.
Błędy RODO. Najczęstsze błędy popełniane przez firmy
Brak świadomości o RODO
Pierwszy, i być może najbardziej podstawowy, błąd polega na braku świadomości lub zrozumienia RODO. Mimo że rozporządzenie to jest już obowiązujące od kilku lat, niektóre firmy nadal nie do końca rozumieją, co oznaczają te regulacje dla ich działalności.
Firmy muszą przestrzegać szeregu specyficznych zasad dotyczących danych osobowych zgodnie z skomplikowanymi wymogami RODO. Bez odpowiedniego zrozumienia tych zasad, firmy są narażone na ryzyko niezgodności z prawem i potencjalne kary.
Niewłaściwe przechowywanie i zabezpieczanie danych
Innym powszechnym błędem jest niewłaściwe przechowywanie i zabezpieczanie danych osobowych. Dane te muszą być przechowywane bezpiecznie, aby zapobiec ich utracie lub kradzieży. W praktyce oznacza to, że firmy muszą zastosować odpowiednie środki bezpieczeństwa, takie jak szyfrowanie, a także regularnie aktualizować i testować swoje systemy bezpieczeństwa.

Brak skutecznej polityki retencji danych
Brak skutecznej polityki retencji danych to kolejny błąd, który firmy często popełniają. RODO wymaga od firm przechowywania danych osobowych tylko przez określony czas. Dane te powinny być przechowywane tylko tak długo, jak długo jest to konieczne do celów, dla których zostały zebrane. Bez jasno zdefiniowanej polityki retencji danych, firmy mogą przechowywać dane zbyt długo. Mogą też przechowywać je zbyt krótko. Taka sytuacja może prowadzić do niezgodności z prawem.
Nieaktualizowanie polityki ochrony danych
Prawo o ochronie danych jest dynamicznym obszarem, który ciągle się rozwija i zmienia. Firmy, które nie aktualizują regularnie swoich polityk i procedur, mogą łatwo znaleźć się w trudnej sytuacji. Może się okazać, że nie są już zgodne z najnowszymi wymogami. To oznacza, że firmy muszą aktywnie monitorować zmiany w prawie i odpowiednio dostosowywać swoje działania.
Konsekwencje popełniania błędów
Kary finansowe
Jedną z najbardziej dotkliwych konsekwencji niezgodności z RODO są kary finansowe. Organizacje, które naruszają przepisy RODO, mogą być narażone na grzywny. Kary mogą wynosić do 20 milionów euro lub do 4% ich globalnego obrotu rocznego, w zależności od tego, która wartość jest wyższa. Przykładowo, w 2019 roku, brytyjski Information Commissioner’s Office nałożył karę. Była to kara w wysokości 204 milionów euro nałożona na linie lotnicze British Airways za naruszenie RODO.
Utrata zaufania klientów
Utrata zaufania klientów jest inną ważną konsekwencją niewłaściwego zarządzania danymi.
Kiedy klienci dowiedzą się, że ich dane nie były odpowiednio chronione, mogą zrezygnować. Mogą zdecydować się na niekorzystanie z usług firmy w przyszłości. Taka utrata zaufania może prowadzić do utraty klientów i spadku sprzedaży.
Potencjalne straty biznesowe
Na końcu, niezgodność z RODO i niewłaściwe zarządzanie danymi może prowadzić do ogromnych strat biznesowych. Obejmują one nie tylko potencjalne grzywny i utratę klientów, ale także koszty związane z naprawą błędów. Do tych kosztów można zaliczyć implementację nowych systemów bezpieczeństwa i szkolenie personelu.
Jak unikać najczęstszych błędów
Szczegółowe zrozumienie i stosowanie się do zasad RODO
Pierwszym krokiem do uniknięcia tych błędów jest zrozumienie i przestrzeganie zasad RODO.
Firmy powinny zapewnić, że wszystkie osoby, które mają do czynienia z danymi osobowymi, są świadome przepisów RODO. Powinny także wiedzieć, jak je stosować. Firmy powinny regularnie przeprowadzać szkolenia z zakresu ochrony danych, aby personel był na bieżąco z najnowszymi przepisami.
Implementacja i przestrzeganie efektywnej polityki retencji danych
Firmy również powinny opracować i wdrożyć skuteczną politykę retencji danych, określającą, jak długo przechowywać różne rodzaje danych. Firmy powinny regularnie przeglądać i aktualizować tę politykę, aby zapewnić jej zgodność z obowiązującymi przepisami.

Regularne przeglądy i aktualizacje polityk i procedur związanych z danymi
Kolejnym ważnym krokiem jest regularne przeglądanie i aktualizowanie polityk i procedur związanych z danymi. To obejmuje nie tylko politykę retencji danych, ale także politykę bezpieczeństwa danych i procedury dotyczące zgody na przetwarzanie danych. Regularne przeglądy pomogą upewnić się, że polityki i procedury firmy są na bieżąco z najnowszymi wymogami prawnymi.
Szkolenie personelu w zakresie zasad RODO i retencji danych
Ostatni, ale nie mniej ważny, krok polega na zapewnieniu odpowiedniego szkolenia całemu personelowi w zakresie zasad RODO i retencji danych. To nie tylko pomoże zapobiec błędom. Pomocne jest to także w zrozumieniu przez pracowników, dlaczego te zasady są tak ważne. Muszą również zdać sobie sprawę z konsekwencji ich niedostosowania się do nich.
Podsumowanie
Przestrzeganie RODO i skuteczna retencja danych są kluczowe dla utrzymania zgodności z prawem i ochrony zaufania klientów. Przez unikanie najczęściej popełnianych błędów, firmy mogą lepiej zarządzać swoimi danymi, minimalizować ryzyko i maksymalizować korzyści płynące z posiadania danych. To jest proces ciągłego uczenia się i dostosowywania, ale wysiłek jest tego wart, biorąc pod uwagę potencjalne konsekwencje.
Witaj w Wizards! Jesteśmy specjalistami od ochrony danych, dostarczając skuteczne narzędzia do wykrywania, anonimizacji i retencji danych osobowych. Nasze usługi zapewniają pełną zgodność z RODO w zakresie ochrony danych osobowych.
Posiadamy 25-letnie doświadczenie w tworzeniu systemów do obsługi wrażliwych danych w różnych sektorach, wykorzystując najnowsze technologie, takie jak big data i uczenie maszynowe. Jako zaangażowani programiści i współwłaściciele firmy, chcemy odciążyć innych specjalistów od wyzwań związanych z przestrzeganiem RODO. Umożliwiając im tym samym skupienie się na ich własnych zadaniach.
Jeżeli poszukujesz narzędzi do zarządzania danymi osobowymi i wrażliwymi, zapraszamy do kontaktu. Umówmy się na rozmowę. To pierwszy krok, aby Twoja firma mogła uniknąć potencjalnych kar. Skontaktuj się z nami już dziś!
Poznaj konsekwencje z naruszania RODO
Nieprzestrzeganie zasad RODO, takich jak niewłaściwe ograniczenie przechowywania danych (retencji) czy niewłaściwa anonimizacja, prowadząc do naruszenia poufności, może prowadzić do sankcji administracyjnych i nałożenia kar finansowych.
Zgodnie z art. 83 ust. 5 RODO, naruszenia przepisów dotyczących kwestii związanych z zasadami ogólnymi, takimi jak retencja czy minimalizacja, mogą skutkować nałożeniem kary pieniężnej do 20 000 000 EUR, a dla przedsiębiorstw – do 4% całkowitego rocznego światowego obrotu z poprzedniego roku obrotowego. W przypadku obu kwot, zastosowanie znajduje ta wyższa.
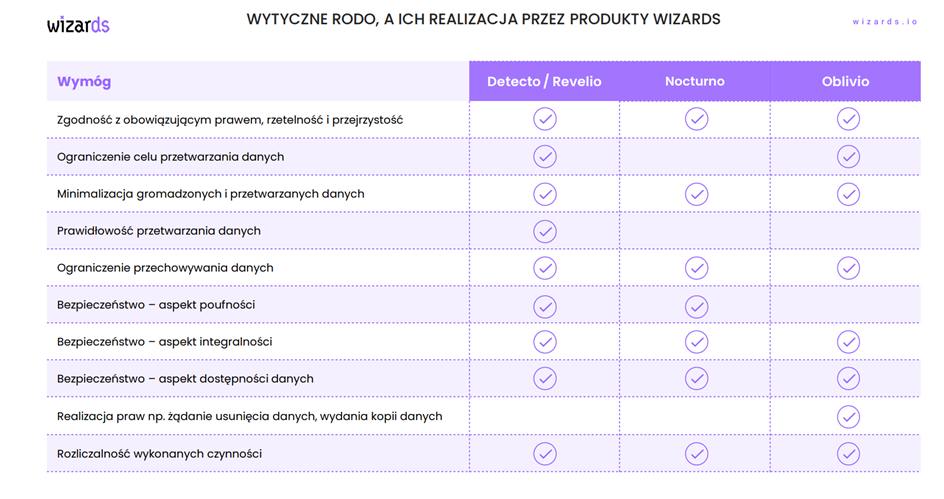
Kluczowe aspekty przetwarzania danych to: zgodność z prawem, rzetelność, przejrzystość, ograniczenie celu i minimalizacja danych, ich prawidłowość i bezpieczeństwo, w tym poufność, integralność i dostępność. Niezbędne jest także uwzględnienie praw, jak usuwanie czy kopiowanie danych, oraz odpowiedzialność za przetwarzanie.
Sprawdź nasze narzędzia
Wybierając Wizards, chronisz swoją firmę przed potencjalnie ogromnymi kosztami wynikającymi z naruszenia przepisów RODO. Można to zobrazować na przykładzie British Airways, które w 2019 roku zostało ukarane karą w wysokości 204 mln euro za naruszenie danych osobowych. Dzięki naszej współpracy, możesz być pewien bezpieczeństwa swoich finansów, przedsiębiorstwa, pracowników i klientów.
- Detecto, system monitorujący dane osobowe i wrażliwe w bazach danych, wspierający procesy anonimizacji i retencji.
- Revelio, skuteczne rozwiązanie do identyfikacji danych osobowych i wrażliwych w dokumentach oraz poczcie elektronicznej, promujące cyfryzację procesów biznesowych.
- Nocturno, zaawansowany system do anonimizacji danych osobowych w systemach informatycznych, zachowujący spójność danych między różnymi systemami.
- Oblivio, dedykowany system do zarządzania retencją danych osobowych w organizacji.
Z Wizards, zapewnisz zgodność z RODO, ochronisz swoją firmę przed kosztownymi karami związanymi z naruszeniem przepisów i zabezpieczysz nie tylko swoje finanse, ale także firmę, pracowników i klientów.
Praktyczne zastosowanie naszych narzędzi
Nasze narzędzia mają realne zastosowanie, które przekłada się na codzienne funkcjonowanie firm. Przedstawiamy poniżej konkretne przykłady.
Detecto. Firma z sektora telekomunikacji korzystała z zaawansowanego rozwiązania klasy ERP jednego z czołowych dostawców. Podczas audytu, IT musiało zlokalizować miejsca w systemie ERP, w którym przechowywane są dane osobowe. Detecto z Wizards przeskanowało bazy danych systemu i dostarczyło raport z lokalizacjami danych osobowych i finansowych.
Revelio. W firmie ubezpieczeniowej, mimo zastosowania różnych narzędzi bezpieczeństwa, doszło do wycieku danych klientów i informacji finansowych. Revelio pomogło zidentyfikować ponad 1000 plików zawierających ponad 100 nazwisk klientów wraz z numerami kont bankowych, zgromadzonych w repozytorium SharePoint i na komputerach osobistych.
Nocturno. Klient korzystał z 20 różnych systemów informatycznych. Dlatego Wizards Nocturno zautomatyzował proces tworzenia środowisk testowych i developerskich, tak, że podczas tworzenia, dane osobowe i wrażliwe były anonimizowane. Co więcej, anonimizacja nie zmienia parametrów jakościowych i ilościowych danych, co pozwoliło na bezpieczne testowanie i rozwój oprogramowania.
Oblivio. Instytucja publiczna przetwarzała dane swoich pracowników. Oblivio pomogło zidentyfikować, które dane powinny być usunięte zgodnie z przepisami o retencji danych. Narzędzie zadbało również o anonimizację danych pracowników, które powinny być usunięte z systemów kadrowych.
Chcesz dowiedzieć się więcej o praktycznym zastosowaniu naszych narzędzi? Skontaktuj się z nami na rozmowę. Mamy dziesiątki innych przykładów!
Modele współpracy
Zabezpiecz swoją firmę jednym ruchem. Odkryj nasze opcje współpracy i umów rozmowę, aby zabezpieczyć swoje przedsiębiorstwo.
Opcje Współpracy:
- Detecto – Identyfikacja danych osobowych w trzech wybranych bazach danych za 10 000 PLN.
- Revelio – Identyfikacja danych osobowych w plikach zasobu współdzielonego (do 100 000 plików) za 10 000 PLN.
- Oblivio – Informacja o ilości danych osobowych, które podlegają retencji, przechowywanych w Twojej bazie (dotyczy 1 procesu, max 3 systemy) za 10 000 PLN.
Oferujemy opcje jednorazowego użytku lub subskrypcji na okres miesiąca lub roku.

Z nami warto!
Przepisy RODO mogą być trudne do zrozumienia i zastosowania. W Wizards, stawiamy na przystępność i skuteczność. Nasze narzędzia Detecto, Revelio, Nocturno i Oblivio, dostosowane do Twoich potrzeb, zapewniają efektywne zarządzanie danymi osobowymi i pełną zgodność z RODO.
Nie pozwól na hamowanie rozwoju Twojej firmy przez strach przed RODO. Dlatego też z nami zyskujesz pewność i bezpieczeństwo, co umożliwia Ci skupienie się na tym, co najważniejsze – Twoim biznesie. Tak więc wybierz Wizards, wybierz jedyną słuszną ochronę. Następnie umów się na rozmowę z nami już dziś i zabezpiecz swoją firmę przed konsekwencjami naruszenia RODO.
Przetwarzanie danych osobowych to nieodłączny element rzeczywistości cyfrowej. Firmy stoją przed wieloma wyzwaniami. Cyberprzestępczość stanowi poważne zagrożenie. Społeczeństwo staje się coraz bardziej świadome swojej prywatności. Regulacje prawne, w tym RODO, stawiają konkretne wymogi. Firmy muszą podejść do nich elastycznie i odpowiedzialnie. Jednak trudno określić wpływ tych elementów na rozwój sztucznej inteligencji (SI).
Cyberprzestępczość
Cyberprzestępczość stanowi wielkie wyzwanie współczesnego świata. Nasilenie tego problemu rośnie z każdym rokiem. W języku biznesu powszechne stały się terminy takie jak ataki hakerskie, phishing i ransomware. Firmy przetwarzające dane osobowe muszą inwestować w systemy bezpieczeństwa IT. Muszą też szkolić swoje zespoły. To pozwala skutecznie przeciwdziałać zagrożeniom. Bezpieczeństwo danych to priorytet dla każdego biznesu.
Świadomość społeczna na temat prywatności
Prawo do prywatności to podstawowe prawo człowieka. W erze cyfryzacji staje się ono coraz ważniejsze. Klienci są coraz bardziej świadomi swoich praw. Oczekują od firm transparentności w przetwarzaniu danych. Firmy, które nie spełniają tych oczekiwań, ryzykują utratę zaufania klientów. Może to z kolei prowadzić do utraty ich lojalności.
Prawo do prywatności to podstawowe prawo człowieka. Umożliwia kontrolowanie informacji o sobie. Zabezpiecza przed ich niewłaściwym wykorzystaniem. RODO, jako europejski regulamin, kluczowo traktuje to prawo.
RODO zobowiązuje firmy do ochrony przetwarzanych danych, a także firmy muszą informować osoby o celach przetwarzania ich danych. Muszą też umożliwić im dostęp do tych danych.
RODO wprowadza prawo do bycia zapomnianym, co oznacza, że osoba może zażądać usunięcia swoich danych w określonych sytuacjach. Dodatkowo, prawo do przenoszenia danych to kolejny element RODO, który umożliwia przenoszenie danych między usługodawcami.
Więc, prawo do prywatności w kontekście RODO to kontrola nad danymi osobowymi. To ochrona przed ich niewłaściwym przetwarzaniem.
Rosnące wymagania prawne
RODO to kluczowy regulamin dotyczący przetwarzania danych. Wprowadza on wiele wymogów, które firmy muszą spełnić. Za naruszenie tych regulacji grożą surowe sankcje. Mogą one wynieść nawet do 20 milionów euro. Alternatywnie, może to być 4% globalnego obrotu firmy. To dowodzi powagi prawa do prywatności w Unii Europejskiej. Firmy muszą więc poświęcić zasoby na zapewnienie zgodności z RODO. Jest to niezbędne także dla innych przepisów prawnych.
RODO a sztuczna inteligencja
Sztuczna inteligencja to obszar postępu i innowacji. Musi jednak przestrzegać przepisów RODO. Firmy mają obowiązek informować klientów o przetwarzaniu ich danych przez algorytmy. Muszą też zapewnić “prawo do wyjaśnienia” automatycznych decyzji. Takie wymogi mogą spowolnić rozwój SI. Jednocześnie, mogą skłonić do tworzenia bardziej “przejrzystych” i etycznych modeli SI.

Rozwiązania i przyszłość
Wyzwania w przetwarzaniu danych są duże, ale pokonalne. Nowe technologie mogą zwiększyć prywatność i bezpieczeństwo danych. Firmy inwestujące w zaawansowaną SI muszą integrować zasady RODO na etapie projektowania. To jest tzw. privacy by design. Szkolenie pracowników i budowanie kultury szacunku dla prywatności jest kluczowe. To dotyczy wszystkich szczeblach organizacji.
Podsumowanie
Dane stały się nowym “złotem” w naszym świecie. Umiejętność ich zarządzania to klucz do sukcesu. RODO może stanowić wyzwanie, ale też daje szansę na budowanie zaufania. Wzrost lojalności klientów jest możliwy dzięki temu. Obserwujemy dynamiczny rozwój technologii, w tym sztucznej inteligencji. Podejście do danych, które łączy innowacyjność i etykę, będzie kluczem do przyszłego sukcesu. Jak myślicie kto wygra walkę RODO czy sztuczna inteligencja?
W dzisiejszych czasach dane osobowe stały się nieodłącznym elementem naszego życia. Większość z nas przekazuje swoje dane podczas zakładania konta w serwisach internetowych, rejestrowania się na konferencje, dokonując zakupów w sklepach czy korzystając z aplikacji mobilnych.
Musimy mieć na uwadze, że również w naszej codziennej pracy biurowej wykorzystujemy dane osobowe naszych klientów, partnerów biznesowych czy współpracowników.
Warto zwrócić uwagę, że ochrona danych wrażliwych w polskich firmach jest aktualnie jednym z większych problemów związanych z bezpieczeństwem informacji. Najczęściej dane wrażliwe nielegalnie udostępniają osoby związane z daną firmą, takie jak pracownicy lub kontrahenci. Często do takich udostępnień dochodzi w sposób przypadkowy lub nieświadomy.
Według raportu “Stan Bezpieczeństwa Wewnętrznego 2021” opublikowanego przez CERT Polska, w 2020 roku w Polsce odnotowano 373 incydenty związane z naruszeniem bezpieczeństwa informacji, w tym 187 incydentów dotyczących wycieku danych. W ramach tych incydentów skradziono ponad 1,6 miliarda rekordów.
Dlatego ważne jest, aby firmy działały w sposób zapobiegawczy. Stosując odpowiednie środki bezpieczeństwa, jak również szkoliły swoich pracowników w zakresie bezpieczeństwa informacji, aby zmniejszyć ryzyko wycieku danych.
Co to są dane wrażliwe i dane osobowe?
Dane osobowe to informacje, które pozwalają na identyfikację konkretnej osoby. Wśród takich danych znajdują się między innymi: imię i nazwisko, numer PESEL, adres zamieszkania, adres e-mail, numer telefonu, a także dane związane z pracą, takie jak stanowisko, nazwa firmy, czy wynagrodzenie.
Dane wrażliwe to natomiast szczególna kategoria danych osobowych, która wymaga dodatkowej ochrony ze względu na ich charakter. Są to informacje dotyczące zdrowia, pochodzenia, przekonań politycznych, religijnych lub światopoglądowych, a także dane dotyczące życia seksualnego, czy też przestępstw lub wyroków sądowych.
Zgodnie z RODO i Kodeksem cywilnym, zbieranie, przetwarzanie oraz przechowywanie danych osobowych i wrażliwych wymaga zgody osoby, której dane dotyczą. Należy też stosować odpowiednie środki ochrony tych danych, aby uniknąć ich nieuprawnionego ujawnienia czy wykorzystania.

Dlaczego warto chronić i zabezpieczać dane wrażliwe oraz dane osobowe?
Ochrona danych osobowych i wrażliwych jest niezwykle ważna ze względu na wiele zagrożeń, jakie mogą wynikać z ich nieuprawnionego ujawnienia lub wykorzystania. Poniżej przedstawiamy kilka powodów, dlaczego warto chronić i zabezpieczać dane wrażliwe oraz dane osobowe:
- Prywatność – każdy ma prawo do prywatności i ochrony swoich danych osobowych. Bezpieczeństwo tych danych pozwala na uniknięcie nieuprawnionego ujawnienia informacji prywatnych, a tym samym utrzymanie prywatności i godności osoby.
- Bezpieczeństwo finansowe – dane wrażliwe, takie jak numery kont bankowych czy karty kredytowej, mogą być wykorzystane do kradzieży tożsamości lub innych form oszustwa finansowego. Ochrona tych danych jest zatem kluczowa dla zapewnienia bezpieczeństwa finansowego.
- Bezpieczeństwo zdrowotne – dane medyczne są uznawane za szczególnie wrażliwe i wymagają szczególnej ochrony ze względu na ich prywatny charakter. Nieuprawnione ujawnienie tych danych może prowadzić do dyskryminacji, a także utrudnić dostęp do ubezpieczenia zdrowotnego czy leczenia.
- Ochrona przed nadużyciami – przetwarzanie danych osobowych przez podmioty trzecie bez wyraźnej zgody osoby, której dane dotyczą, może prowadzić do nadużyć. Ochrona danych osobowych chroni przed takimi sytuacjami.
- Zgodność z przepisami – w wielu krajach istnieją przepisy prawne, które wymagają ochrony danych osobowych i wrażliwych. Niedopełnienie tych obowiązków może prowadzić do kar finansowych lub innych konsekwencji prawnych.
Czy w Twojej firmie dane nie są chronione? Sprawdź jak to łatwo naprawić!
Revelio to narzędzie do wykrywania danych osobowych oraz innych danych wrażliwych we współdzielonych zasobach plikowych, dokumentach zlokalizowanych na komputerach osobistych, poczcie e-mail.
Narzędzie to pozwala identyfikować procesy biznesowe, które generują dokumenty i rekomendować ich dygitalizacje. Skontaktuj się z nami, a zabezpieczymy Twoją firmę przed niepożądanym wyciekiem danych. Wystarczy tylko umówić się z nami na rozmowę, a uchronimy Ciebie i zabezpieczymy Twoją firmę przed nielegalnym wykorzystaniem danych.
Chcesz wdrożyć narzędzia do ochrony wrażliwych danych? Jak przygotować firmę na ten proces?
- Zidentyfikuj wrażliwe dane: Przede wszystkim należy zidentyfikować, jakie rodzaje danych wrażliwych są przechowywane w firmie. Należy przyjrzeć się dokumentom, bazom danych, programom, w których te dane są przetwarzane i przechowywane.
- Przeprowadź audyt bezpieczeństwa: W celu dokładnego określenia potrzeb ochrony danych, warto przeprowadzić audyt bezpieczeństwa. Pozwoli on na dokładne określenie ryzyka i wykrycie ewentualnych luk w systemie bezpieczeństwa.
- Opracuj politykę ochrony danych: Należy opracować politykę ochrony danych, która określi, jakie kroki należy podjąć, aby chronić wrażliwe dane. Polityka ta powinna określać zasady dotyczące zarządzania, przetwarzania, przechowywania i usuwania danych.
- Wdrożenie narzędzi ochrony danych: Na podstawie wyników audytu i opracowanej polityki, należy wybrać odpowiednie narzędzia do ochrony danych. Pomogą one w zabezpieczeniu danych przed nieuprawnionym ujawnieniem lub wykorzystaniem.
- Przeprowadź szkolenie pracowników: Należy przeprowadzić szkolenie pracowników, aby zwiększyć ich świadomość na temat zagrożeń związanych z wrażliwymi danymi. Dodatkowo należy przeszkolić ich jak postępować w przypadku podejrzenia naruszenia bezpieczeństwa danych.
- Monitoruj i aktualizuj system bezpieczeństwa: W celu utrzymania bezpieczeństwa wrażliwych danych, konieczne jest ciągłe monitorowanie i aktualizacja systemu bezpieczeństwa.
Wdrożenie narzędzi do ochrony wrażliwych danych to proces, który wymaga odpowiedniego przygotowania i zaplanowania. Warto podjąć te kroki, aby zapewnić odpowiednią ochronę wrażliwych danych w firmie i uniknąć ryzyka ich nieuprawnionego ujawnienia lub wykorzystania. Specjalnie dla tego procesu stworzyliśmy „Revelio”. Więcej na ten temat: https://wizards.io/revelio/

Niedługo minie dwadzieścia lat od momentu, kiedy dołączyłem do świata IT. Przez ten okres obserwowałem, jak zmienia się to środowisko, jak rozwijają się procesy wytwórcze i jakie nowe narzędzia są wykorzystywane. Z czasem wiele procesów, m.in. powtarzalne zadania, ulegało automatyzacji. Firmy wdrażały Continuous Integration i Continuous Delivery. Wszystkiemu przewodziła jedna myśl: pozwolić twórcom oprogramowania skupić się na rozwoju systemów i biznesie.
Wejście RODO
Wejście RODO wstrząsnęło światem IT i narzuciło nowe reguły gry. Proces wytwórczy stał się bardziej skomplikowany, operowanie na danych osobowych stało się dużym ryzykiem, które trzeba było zaadresować. Pracując w software house widzieliśmy te problemy wyraźnie, ponieważ występowały w każdym z naszych projektów. Teoretycznie byliśmy przygotowani na wejście RODO. Byliśmy po odpowiednich kursach, firma zbroiła się w dokumenty i rejestry. W praktyce okazało się, że obostrzenia prawne i niepewność związana z wejściem w życie tego rozporządzenia, wpłynęły na naszą codzienną pracę. Mój sen o developmencie bez przeszkód, gdzie możemy skupić się tylko na produkcji oprogramowania, prysnął.
Krótko po wdrożeniu RODO rozpoczęło się szukanie rozwiązań. Narzędzia, które udawało nam się znaleźć, nie odpowiadały na nasze potrzeby projektowe, ponieważ na co dzień rozwijaliśmy całe, zintegrowane, tworzone w różnych technologiach ekosystemy wymieniające się danymi osobowymi. Obsługa każdego przypadku, ręcznie i z osobna, była dla mnie nie do przyjęcia. Czułem się tak, jakbym cofnął się o dwie dekady.
Zmiana status quo
Ostatecznie w firmie wyłoniła się grupa ludzi, która postawiła sobie za cel zmianę status quo. Wiedzieliśmy, czego potrzebujemy i jak możemy ten plan zrealizować. Z takim wyzwaniem nigdy wcześniej się nie mierzyliśmy. Wspólnie jednak udało nam się stworzyć zestaw narzędzi, który był dla nas wybawieniem.
Anonimizacja danych
Zaczęliśmy od anonimizacji danych na środowiskach testowych. Stworzyliśmy narzędzie, które było w stanie obsłużyć wiele aplikacji na raz, wziąć pod uwagę polską specyfikę i wykonać swoją pracę wydajnie.
Wytworzone rozwiązanie miało obsługiwać wszystkie nasze projekty, dlatego priorytetem była wysoka konfigurowalność i możliwość dostosowania do różnych wymogów. Anonimizację włączyliśmy w procesy Continuous Integration i szybko wdrożyliśmy je w naszych projektach. Okazało się, że te najbardziej bolesne dla nas aspekty RODO są obsługiwane automatycznie i przestały spędzać sen z powiek zespołowi developerskiemu. Zupełnie tak, jakby ten obszar RODO przestał nas dotyczyć.
Retencja danych osobowych
Kolejnym krokiem była retencja danych osobowych, która jest niezbędna w prawie każdym systemie. Zadbanie o ten aspekt w pojedynczej aplikacji jest łatwe. Wykonanie retencji danych w dziesięciu zintegrowanych systemach jest znacznie trudniejsze, a przy stu – już praktycznie niemożliwe. Było dla nas jasne, że nie chcemy powtarzać tej samej funkcjonalności we wszystkich systemach, które wytwarzamy. W ten sposób narodziło się kolejne narzędzie, które zdejmowało z nas kolejny problem.
Wszystko wróciło na dobre tory, tak jak sobie wymarzyłem. Na szczęście RODO okazało się być jedynie wybojem na drodze w naszych projektach.
Wizards
Z tą też myślą założyliśmy startup. Doszliśmy do wniosku, że problemy, z którymi borykaliśmy się do tej pory dotyczą wielu zespołów developerskich, a my mamy klucz do ich rozwiązania. Dlatego też postanowiliśmy stworzyć nocturno i oblivio, o których już wkrótce więcej przeczytacie m.in. na naszym firmowym profilu Wizards.
Artur Żórawski, Founder&CTO Wizards