Witaj w Wizards! Jesteśmy specjalistami od ochrony danych, dostarczając skuteczne narzędzia do wykrywania, anonimizacji i retencji danych osobowych. Nasze usługi zapewniają pełną zgodność z RODO w zakresie ochrony danych osobowych.
Posiadamy 25-letnie doświadczenie w tworzeniu systemów do obsługi wrażliwych danych w różnych sektorach, wykorzystując najnowsze technologie, takie jak big data i uczenie maszynowe. Jako zaangażowani programiści i współwłaściciele firmy, chcemy odciążyć innych specjalistów od wyzwań związanych z przestrzeganiem RODO. Umożliwiając im tym samym skupienie się na ich własnych zadaniach.
Jeżeli poszukujesz narzędzi do zarządzania danymi osobowymi i wrażliwymi, zapraszamy do kontaktu. Umówmy się na rozmowę. To pierwszy krok, aby Twoja firma mogła uniknąć potencjalnych kar. Skontaktuj się z nami już dziś!
Poznaj konsekwencje z naruszania RODO
Nieprzestrzeganie zasad RODO, takich jak niewłaściwe ograniczenie przechowywania danych (retencji) czy niewłaściwa anonimizacja, prowadząc do naruszenia poufności, może prowadzić do sankcji administracyjnych i nałożenia kar finansowych.
Zgodnie z art. 83 ust. 5 RODO, naruszenia przepisów dotyczących kwestii związanych z zasadami ogólnymi, takimi jak retencja czy minimalizacja, mogą skutkować nałożeniem kary pieniężnej do 20 000 000 EUR, a dla przedsiębiorstw – do 4% całkowitego rocznego światowego obrotu z poprzedniego roku obrotowego. W przypadku obu kwot, zastosowanie znajduje ta wyższa.
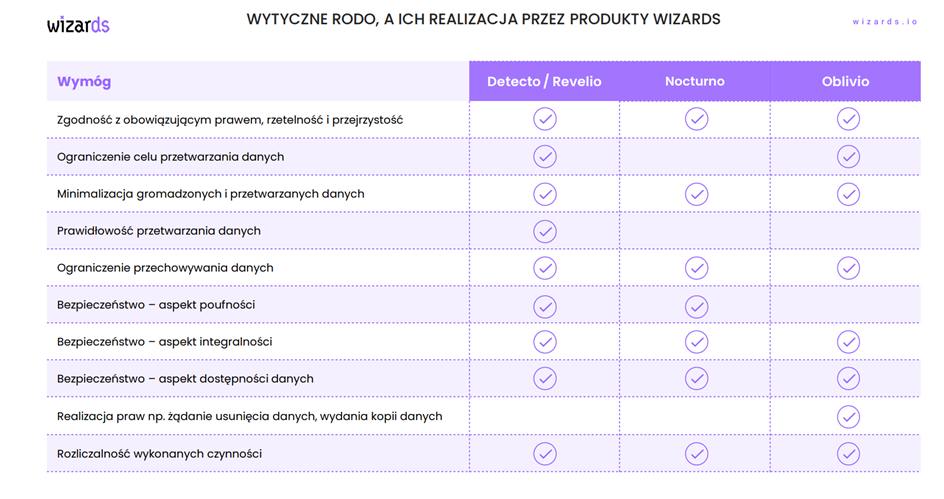
Kluczowe aspekty przetwarzania danych to: zgodność z prawem, rzetelność, przejrzystość, ograniczenie celu i minimalizacja danych, ich prawidłowość i bezpieczeństwo, w tym poufność, integralność i dostępność. Niezbędne jest także uwzględnienie praw, jak usuwanie czy kopiowanie danych, oraz odpowiedzialność za przetwarzanie.
Sprawdź nasze narzędzia
Wybierając Wizards, chronisz swoją firmę przed potencjalnie ogromnymi kosztami wynikającymi z naruszenia przepisów RODO. Można to zobrazować na przykładzie British Airways, które w 2019 roku zostało ukarane karą w wysokości 204 mln euro za naruszenie danych osobowych. Dzięki naszej współpracy, możesz być pewien bezpieczeństwa swoich finansów, przedsiębiorstwa, pracowników i klientów.
- Detecto, system monitorujący dane osobowe i wrażliwe w bazach danych, wspierający procesy anonimizacji i retencji.
- Revelio, skuteczne rozwiązanie do identyfikacji danych osobowych i wrażliwych w dokumentach oraz poczcie elektronicznej, promujące cyfryzację procesów biznesowych.
- Nocturno, zaawansowany system do anonimizacji danych osobowych w systemach informatycznych, zachowujący spójność danych między różnymi systemami.
- Oblivio, dedykowany system do zarządzania retencją danych osobowych w organizacji.
Z Wizards, zapewnisz zgodność z RODO, ochronisz swoją firmę przed kosztownymi karami związanymi z naruszeniem przepisów i zabezpieczysz nie tylko swoje finanse, ale także firmę, pracowników i klientów.
Praktyczne zastosowanie naszych narzędzi
Nasze narzędzia mają realne zastosowanie, które przekłada się na codzienne funkcjonowanie firm. Przedstawiamy poniżej konkretne przykłady.
Detecto. Firma z sektora telekomunikacji korzystała z zaawansowanego rozwiązania klasy ERP jednego z czołowych dostawców. Podczas audytu, IT musiało zlokalizować miejsca w systemie ERP, w którym przechowywane są dane osobowe. Detecto z Wizards przeskanowało bazy danych systemu i dostarczyło raport z lokalizacjami danych osobowych i finansowych.
Revelio. W firmie ubezpieczeniowej, mimo zastosowania różnych narzędzi bezpieczeństwa, doszło do wycieku danych klientów i informacji finansowych. Revelio pomogło zidentyfikować ponad 1000 plików zawierających ponad 100 nazwisk klientów wraz z numerami kont bankowych, zgromadzonych w repozytorium SharePoint i na komputerach osobistych.
Nocturno. Klient korzystał z 20 różnych systemów informatycznych. Dlatego Wizards Nocturno zautomatyzował proces tworzenia środowisk testowych i developerskich, tak, że podczas tworzenia, dane osobowe i wrażliwe były anonimizowane. Co więcej, anonimizacja nie zmienia parametrów jakościowych i ilościowych danych, co pozwoliło na bezpieczne testowanie i rozwój oprogramowania.
Oblivio. Instytucja publiczna przetwarzała dane swoich pracowników. Oblivio pomogło zidentyfikować, które dane powinny być usunięte zgodnie z przepisami o retencji danych. Narzędzie zadbało również o anonimizację danych pracowników, które powinny być usunięte z systemów kadrowych.
Chcesz dowiedzieć się więcej o praktycznym zastosowaniu naszych narzędzi? Skontaktuj się z nami na rozmowę. Mamy dziesiątki innych przykładów!
Modele współpracy
Zabezpiecz swoją firmę jednym ruchem. Odkryj nasze opcje współpracy i umów rozmowę, aby zabezpieczyć swoje przedsiębiorstwo.
Opcje Współpracy:
- Detecto – Identyfikacja danych osobowych w trzech wybranych bazach danych za 10 000 PLN.
- Revelio – Identyfikacja danych osobowych w plikach zasobu współdzielonego (do 100 000 plików) za 10 000 PLN.
- Oblivio – Informacja o ilości danych osobowych, które podlegają retencji, przechowywanych w Twojej bazie (dotyczy 1 procesu, max 3 systemy) za 10 000 PLN.
Oferujemy opcje jednorazowego użytku lub subskrypcji na okres miesiąca lub roku.

Z nami warto!
Przepisy RODO mogą być trudne do zrozumienia i zastosowania. W Wizards, stawiamy na przystępność i skuteczność. Nasze narzędzia Detecto, Revelio, Nocturno i Oblivio, dostosowane do Twoich potrzeb, zapewniają efektywne zarządzanie danymi osobowymi i pełną zgodność z RODO.
Nie pozwól na hamowanie rozwoju Twojej firmy przez strach przed RODO. Dlatego też z nami zyskujesz pewność i bezpieczeństwo, co umożliwia Ci skupienie się na tym, co najważniejsze – Twoim biznesie. Tak więc wybierz Wizards, wybierz jedyną słuszną ochronę. Następnie umów się na rozmowę z nami już dziś i zabezpiecz swoją firmę przed konsekwencjami naruszenia RODO.

Czy wiesz, w jaki sposób skutecznie
zarządzać procesem retencji danych?
Kiedy pomyśleć o automatyzacji tego
procesu?
Jak wygląda proces retencji danych od
strony IT i jakie wyzwania mogą
się z nim wiązać?
W trzecim już artykule z cyklu “RODO w IT” wspólnie z Mirkiem pochylimy się nad tematem wyzwań związanych z retencją danych.
Z artykułu dowiesz się m.in.:
- Na co zwrócić uwagę myśląc o wdrożeniu lub usprawnieniu procesu retencji danych zarówno po stronie IT, jak i compliance
- Jak poradzić sobie z retencją w sytuacji, w której mamy więcej niż 2 systemy w organizacji
- Jak skutecznie usuwać dane zgodnie z wymogami RODO i uwzględnieniem wszelkich podstaw prawnych
Zapraszamy do lektury!
Artur Żórawski, Founder i CTO Wizadrs
Architekt IT z ponad 20 letnim stażem, autor pomysłów na rozwiązania IT do detekcji, anonimizacji i retencji danych.
i
dr Mirosław Gumularz, Radca Prawny GKK Gumularz Kozik
Audytor wewnętrzny systemu zarządzania bezpieczeństwem informacji wg normy ISO 27001:2013. Członek Grupy Roboczej ds. Ochrony Danych Osobowych przy Ministerstwie Cyfryzacji.
———————————————————
Skuteczne zarządzanie procesem retencji danych
Mirosław Gumularz (MG): W poprzednich dwóch artykułach opowiadaliśmy o tym, co RODO zmieniło w branży IT, a także o anonimizacji, temacie, który do tej pory zdecydowanie był bliższy osobom po tej “technicznej” stronie. Kolejnym z wymogów RODO, z którym mierzy się dziś większość firm, a w szczególności działy compliance, jest ograniczenie przechowywania danych osobowych, czyli retencja danych. Oczywiście łączy się to z omawianą poprzednio kwestią anonimizacji, która jest środkiem realizacji wymogu czasowego ograniczenia przechowywania danych osobowych i alternatywą dla „fizycznego” usunięcia danych.
Faktem jest, że RODO nie pozwala przetwarzać danych osobowych w nieskończoność. Zazwyczaj nie mówi nam też, ile czasu możemy przetwarzać te dane. Nawet tam, gdzie przepisy prawa, co jest raczej rzadkością, definiują jak długo można przetwarzać dane, na ogół jest cała masa wyjątków. To jest zadanie właśnie dla działów compliance. To one znając cele i kategorie danych, określają okresy ich retencji, czyli przechowywania.
Tutaj sprawa zaczyna się komplikować od strony technicznej, a konkretnie w zakresie kontrolowania procesu usuwania danych z systemów zgodnie z zebranymi zgodami. Niezależnie od długości przetwarzania ustalonej przez osoby odpowiedzialne za compliance, osoby techniczne muszą wiedzieć, że bez względu na to, jak długi ten okres będzie, muszą zmierzyć się z tym, że kiedyś dane będą musiały być usunięte.
Przetwarzanie danych przy założeniu, że nie będziemy mieć narzędzi do ich usuwania, może naruszać regułę zawartą w art. 25 ust. 1 RODO, tj. privacy by design. Ciekawy w tym kontekście jest problem usuwania danych przetwarzanych przy wykorzystaniu technologii Blockchain, który właśnie taki przypadek obrazuje. Pojawia się pytanie, czy można przetwarzać dane skoro wiemy, że kiedyś tam w przyszłości może być problem całkowitego ich usunięcia. Polecam w tym zakresie rekomendację CNIL (francuski organ nadzorczy): Blockchain and the GDPR: Solutions for a responsible use of the blockchain in the context of personal data.
Podsumowując. Chcąc skutecznie zarządzać procesem retencji, trzeba oczywiście dbać o stronę formalno-prawną. To jednak nie wystarczy. Musimy również wiedzieć dokładnie:
- w jakich systemach gromadzone są dane,
- do jakich celów są wykorzystywane
- czy jesteśmy w stanie przypisać ten cel do określonych kategorii danych
- i czy, kiedy oraz w jaki sposób zaplanowana jest ich retencja.
W praktyce oznacza to, że trzeba wiedzieć, jak te dane usunąć i mieć pomysł na to, w jaki sposób to robić w zależności od celów ich przetwarzania.
Dlaczego to jest ważne?
Przykładowo może okazać się, że ta sama kategoria danych (np. nr pesel, ID użytkownika) przetwarzana przy wykorzystaniu tego samego systemu, lub różnych systemów, w zależności od celu przetwarzania będzie mieć różny okres retencji (usuwania danych).
Co więcej może być tak, że w ramach jednego procesu różne kategorie dane mogą mieć różne cele i okresy retencji np. dane zbierane poprzez formularz rejestracji użytkownika. Może być tak, że część z tych danych jest niezbędna do realizacji celu zawarcia umowy, a część z nich np. służy do weryfikacji tożsamości co nie zawsze jest niezbędne do zawarcia umowy.
Artur Żórawski (AŻ): Dodatkowo od strony technicznej jest to o tyle wyzwanie, że często w jednej organizacji jest wielu dostawców rozwiązań informatycznych. Wiele osób uczestniczy tym samym w procesie wytwarzania i rozwijania oprogramowania. Z rozmów z naszymi Klientami wiemy, że często w związku z tym problematyczne staje się zlokalizowanie wszystkich danych użytkowników we wszystkich systemach oraz ich kompleksowa retencja zgodnie z wymogami RODO.
MG: Warto jeszcze dodać, że jednym z wymogów RODO jest podanie na żądanie informacji o źródle danych, czy celu przetwarzania danych osobowych, co w wielu przypadkach jest w tym kontekście problematyczne zwłaszcza, jeśli chodzi o podanie źródła. Pojęcie źródła danych jest bardzo szeroko zdefiniowane w RODO i nie można wykluczyć takiego kierunku wykładni, która obejmuje także “narzędzie”, system wykorzystywany do przetwarzania danych. Dla przykładu w kontekście przetwarzania danych medycznych RODO wskazuje, że:
„Do danych osobowych dotyczących zdrowia należy zaliczyć wszystkie dane o stanie zdrowia osoby, której dane dotyczą, ujawniające informacje o (…)
niezależnie od ich źródła, którym może być na przykład lekarz lub inny pracownik służby zdrowia, szpital, urządzenie medyczne lub badanie diagnostyczne in vitro”.
Kiedy warto zacząć myśleć o automatyzacji procesu?
MG: Dochodzimy w tym momencie do pytania: w jaki sposób najlepiej tym procesem zarządzić? Faktem jest, że im większa organizacja, tym większym problemem staje się brak odpowiednich narzędzi ułatwiających zarządzanie retencją danych na przykład poprzez automatyzację procesu.
AŻ: To prawda. Pytanie tylko, kiedy na taką automatyzację się zdecydować. Jeżeli chodzi o retencje danych w większych organizacjach trzeba zauważyć, że problem usuwania danych i retencji rośnie wykładniczo wraz ze wzrastającą ilością systemów.
- Jeżeli firma ma jeden system, to retencja jest stosunkowo prosta. Automatyzacja jest niepotrzebna.
- Jeżeli natomiast mamy więcej systemów, a do tego dołożymy dużą ilość celów przetwarzania danych, proces retencji zaczyna być wymagający.
- Przy bardzo dużych organizacjach, gdy tych systemów mamy powyżej stu, bez automatyzacji retencja danych zdaje się praktycznie niemożliwa. Jest to spowodowane wieloma czynnikami, ale głównym z nich jest fakt, że dane są swobodnie przesyłane między systemami i należy zapewnić spójne usunięcie lub anonimizację danych ze wszystkich zintegrowanych aplikacji.
MG: Mówiąc o tym poruszyłeś tak naprawdę kolejny problem. Nie wystarczy ustalić, że technicznie dane można usunąć np. „ręcznie”. Należy ustalić, czy ten sposób usuwania danych jest wystarczający, czy w praktyce będzie wystarczająco efektywny. Jeżeli ten brak efektywności może zrodzić ryzyko dla ludzi, którego źródłem jest naruszenie wymogu usuwania danych (np. ktoś nie zostanie dopuszczony do określonej usługi, bo system go “rozpozna”), sam w sobie może być naruszeniem zasady privacy by design.
Retencja danych z punktu widzenia działów IT
- Retencja danych a kopie systemów
MG: W mojej opinii kwestia retencji, backupu, czy długości przechowywania danych to największe wyzwania na styku IT i compliance. Na ogół prawnicy stawiają bardzo sztywne wymagania. Wszystkie dane kategorii X ze względu na upływ czasu Y mają być usunięte/zaanonimizowane. Niestety w praktyce proces usuwania danych jest dużo bardziej wymagający niż może nam się wydawać.
AŻ: Dokładnie. Stanowisko w tej sprawie zajęło Ministerstwo Cyfryzacji tworząc “RODO – Poradnik dla sektora FINTECH”, gdzie wykazało, że nieusuwanie danych z kopii zapasowych może być uzasadnione:
“W przypadku kopii zapasowych i żądania usunięcia danych na podstawie art. 17 RODO, może realnie zdarzyć się, że nie będzie technicznie możliwe usuniecie danych zawartych w kopii zapasowej lub koszty i wysiłek organizacyjny takiego selektywnego usunięcia danych będą w sposób rażący niewspółmierne do ryzyka naruszenia praw i wolności podmiotu danych. Ponadto selektywne usunięcie danych osobowych z kopii narusza integralność kopii danych a zatem może powodować ryzyko dla praw i wolności innych osób, których dane są przechowywane w ramach tej samej kopii danych.”
Problem, który jednak nadal występuje jest związany z procedurami disaster recovery. Chcąc zobrazować tę kwestię, opowiem o wyzwaniu z zakresu odtwarzania backupu, przed którym stanęliśmy projektując rozwiązanie do retencji danych.
Możemy wyobrazić sobie sytuację, w której dane osobowe Jana Kowalskiego ulegają retencji i są usuwane z bazy danych trzech systemów, w których były przetwarzane. Okazuje się, że jeden z tych systemów już po usunięciu danych ulega katastrofie. W związku z tym musimy odtworzyć jego backup. W efekcie mamy sytuację, w której w systemach dane Jana Kowalskiego zostały usunięte, ale w jednym, tym drugim który uległ awarii dane Jana Kowalskiego nadal istnieją ze względu na konieczność przywrócenia danych sprzed retencji.

Jest to moment, w którym może okazać się, że zapomnimy o konieczności usunięcia danych, które powinny być skasowane.
Projektując rozwiązanie musieliśmy przewidzieć, że takie katastrofy mają szansę się wydarzyć. W takim wypadku, w ramach realizacji procesu retencji danych konieczne jest monitorowanie systemu, a konkretnie sprawdzanie, czy nie rozpoczyna się proces odtwarzania backupu, w wyniku którego przywrócone zostałyby usunięte przez nas dane.
- Prawo do zapomnienia
MG: Kolejnym aspektem, który warto w tym kontekście omówić jest prawo do zapomnienia.Mechanizm retencji, z którego korzystamy musi uwzględniać dwa aspekty usuwania danych:
- usuwanie niezależnie od żądania osoby – np. gdy kończy się cel przetwarzania to niezależnie od żądania usunięcia musimy dane „wyczyścić” (w ustalonych z góry okresach)
- oraz usuwanie ze względu na zgłoszone żądanie usunięcia danych, czy zbliżone do tego (przynajmniej w warstwie konsekwencji technicznych) wycofanie zgody lub zgłoszenie skutecznego sprzeciwu.
AŻ: Tak, wspominaliśmy już o tym nieco powyżej. Jest to wyzwanie zwłaszcza dla dużych organizacji, które w momencie, gdy takie żądanie wpłynie, muszą ustosunkować się do niego i powiedzieć, które dane mogą usunąć zgodnie z prawem, a co do usunięcia których takich podstaw nie ma. Dodatkowo musimy także potwierdzić usunięcie danych.
MG: W przypadku niektórych umów np. umowy o pracę nie jest to takie proste. Dane często nie są ustrukturyzowane.
Dodatkowo dane tej samej osoby mogą znajdować się w innych naszych systemach. Mogą być przetwarzane dla różnych celów i w oparciu o różne podstawy. W jednej sytuacji może to być wspomniana realizacja umowy o pracę, w innej działania promocyjne w oparciu o zgodę dla celów marketingowych, etc. To kolejna sytuacja, w której nasze IT staje przed wyzwaniem.
Co istotne, nie chodzi o to, żeby (tylko) znać cele przetwarzania. Bo to jest stosunkowo proste. Chodzi o to, żeby być w stanie powiązać te cele z konkretnym rekordem. Zwłaszcza, gdy dane nie są przetwarzane w sposób ustrukturyzowany.
Bardzo często zapomina się, że retencji powinny podlegać nie tylko dane podane nam aktywnie np. przez użytkownika systemu ale także te które on wygenerował korzystając z systemu (np. dane w logach) tzw. dane „zaobserwowane” oraz dane które sami wytworzyliśmy na jego temat wnioskując o jego przyszłym zachowaniu (profilowanie).
AŻ: Chcąc zobrazować to wyzwanie wyobraźmy sobie ekosystem połączonych ze sobą wielu systemów informatycznych, które ze sobą współpracują i wymieniają się danymi osobowymi, gdzie jedna osoba może być przetwarzana na wiele sposobów.
Gdzieś w nich są rozsiane te dane, przetwarzane na różnych podstawach, które z kolei są również przechowywane w różnych systemach. Robi nam się z tego całkiem spora sieć zależności. Rozwiązaniem jest jeden, zbiorczy system, który jest w stanie zagregować wszystkie zgody, które dana osoba podpisała.
- Podstawy prawne uniemożliwiające retencję danych
MG: Myśląc o procesie retencji powinniśmy także pamiętać o polityce uwzględniającej wyjątki. Może być np. tak, że zgodnie z procedurą retencji dane Y są automatycznie usuwane po okresie X. Jednocześnie w tym czasie wszczęta jest sprawa sądowa wymagająca dłuższego przetwarzania danych.
AŻ: Dokładnie. Taką sytuację mieliśmy podczas jednego z naszych wdrożeń. Pomimo tego, że umowy wygasły i powinna w tym momencie nastąpić retencja danych Klienta, pojawiła się podstawa prawna, która ten proces uniemożliwiła. Okazało się, że podstawą był pozew sądowy i postępowanie wszczęte wobec właściciela danych. W takiej sytuacji dane osobowe były traktowane jako dowód w rozprawie. Jest to przypadek, który pokazuje, że powinniśmy uwzględniać wszelkie podstawy prawne, nie tylko wynikające bezpośrednio ze zgód.
ABC retencji danych
MG: Podsumowując, jeżeli chodzi o retencję, rozporządzenie RODO wymaga od nas, żebyśmy usuwali dane niezależnie od żądania usunięcia na podstawie wewnętrznie określonych okresów retencji, w powiązaniu z:
- celami przetwarzania,
- kategoriami danych,
- podstawami prawnymi,
- oraz kategoriami podmiotów (pracownik, użytkownik).
Powinniśmy również uwzględniać możliwość wystąpienia specyficznych przypadków, o których mowa powyżej.
AŻ: Projektując, lub wdrażając u siebie narzędzia do retencji danych osobowych zadbajmy o to, żeby:
- łączyły się z wieloma środowiskami i systemami,
- potrafiły wykryć miejsca przechowywania danych i umożliwiły ich usunięcie ze wszystkich systemów zgodnie z żądaniem zapomnienia, lub w momencie zakończenia umowy,
- dawały możliwość powiązania usunięcia z podstawą prawną, w oparciu o którą dane zostały zebrane.
—————————————————-
Odpowiadasz za techniczny lub prawny aspekt ochrony danych osobowych, ochronę bezpieczeństwa danych osobowych lub wrażliwych w swojej organizacji? A może w obszarze, którym się zajmujesz?
Przed nami ostatni z cyklu “RODO w IT” artykuł, w którym porozmawiamy o tym, jak realizować projekty z zakresu sztucznej inteligencji w kontekście privacy&security.
Masz dodatkowe pytania, chcesz wymienić się doświadczeniami, dowiedzieć się więcej o anonimizacji, detekcji i retencji danych osobowych, cykl życia produktów IT w kontekście RODO, w tym privacy by design, a także posłuchać o ciekawych case studies związanych np. z definicją danych osobowych, lub kolejnych etapach wdrażania RODO w Polsce.
Zapisz się już dziś na nasz webinar RODO W IT.
Śledź nasz profil na LinkedIn.
Do usłyszenia!
Artur i Mirek

Niedługo minie dwadzieścia lat od momentu, kiedy dołączyłem do świata IT. Przez ten okres obserwowałem, jak zmienia się to środowisko, jak rozwijają się procesy wytwórcze i jakie nowe narzędzia są wykorzystywane. Z czasem wiele procesów, m.in. powtarzalne zadania, ulegało automatyzacji. Firmy wdrażały Continuous Integration i Continuous Delivery. Wszystkiemu przewodziła jedna myśl: pozwolić twórcom oprogramowania skupić się na rozwoju systemów i biznesie.
Wejście RODO
Wejście RODO wstrząsnęło światem IT i narzuciło nowe reguły gry. Proces wytwórczy stał się bardziej skomplikowany, operowanie na danych osobowych stało się dużym ryzykiem, które trzeba było zaadresować. Pracując w software house widzieliśmy te problemy wyraźnie, ponieważ występowały w każdym z naszych projektów. Teoretycznie byliśmy przygotowani na wejście RODO. Byliśmy po odpowiednich kursach, firma zbroiła się w dokumenty i rejestry. W praktyce okazało się, że obostrzenia prawne i niepewność związana z wejściem w życie tego rozporządzenia, wpłynęły na naszą codzienną pracę. Mój sen o developmencie bez przeszkód, gdzie możemy skupić się tylko na produkcji oprogramowania, prysnął.
Krótko po wdrożeniu RODO rozpoczęło się szukanie rozwiązań. Narzędzia, które udawało nam się znaleźć, nie odpowiadały na nasze potrzeby projektowe, ponieważ na co dzień rozwijaliśmy całe, zintegrowane, tworzone w różnych technologiach ekosystemy wymieniające się danymi osobowymi. Obsługa każdego przypadku, ręcznie i z osobna, była dla mnie nie do przyjęcia. Czułem się tak, jakbym cofnął się o dwie dekady.
Zmiana status quo
Ostatecznie w firmie wyłoniła się grupa ludzi, która postawiła sobie za cel zmianę status quo. Wiedzieliśmy, czego potrzebujemy i jak możemy ten plan zrealizować. Z takim wyzwaniem nigdy wcześniej się nie mierzyliśmy. Wspólnie jednak udało nam się stworzyć zestaw narzędzi, który był dla nas wybawieniem.
Anonimizacja danych
Zaczęliśmy od anonimizacji danych na środowiskach testowych. Stworzyliśmy narzędzie, które było w stanie obsłużyć wiele aplikacji na raz, wziąć pod uwagę polską specyfikę i wykonać swoją pracę wydajnie.
Wytworzone rozwiązanie miało obsługiwać wszystkie nasze projekty, dlatego priorytetem była wysoka konfigurowalność i możliwość dostosowania do różnych wymogów. Anonimizację włączyliśmy w procesy Continuous Integration i szybko wdrożyliśmy je w naszych projektach. Okazało się, że te najbardziej bolesne dla nas aspekty RODO są obsługiwane automatycznie i przestały spędzać sen z powiek zespołowi developerskiemu. Zupełnie tak, jakby ten obszar RODO przestał nas dotyczyć.
Retencja danych osobowych
Kolejnym krokiem była retencja danych osobowych, która jest niezbędna w prawie każdym systemie. Zadbanie o ten aspekt w pojedynczej aplikacji jest łatwe. Wykonanie retencji danych w dziesięciu zintegrowanych systemach jest znacznie trudniejsze, a przy stu – już praktycznie niemożliwe. Było dla nas jasne, że nie chcemy powtarzać tej samej funkcjonalności we wszystkich systemach, które wytwarzamy. W ten sposób narodziło się kolejne narzędzie, które zdejmowało z nas kolejny problem.
Wszystko wróciło na dobre tory, tak jak sobie wymarzyłem. Na szczęście RODO okazało się być jedynie wybojem na drodze w naszych projektach.
Wizards
Z tą też myślą założyliśmy startup. Doszliśmy do wniosku, że problemy, z którymi borykaliśmy się do tej pory dotyczą wielu zespołów developerskich, a my mamy klucz do ich rozwiązania. Dlatego też postanowiliśmy stworzyć nocturno i oblivio, o których już wkrótce więcej przeczytacie m.in. na naszym firmowym profilu Wizards.
Artur Żórawski, Founder&CTO Wizards