W świecie, gdzie informacje są równie cenne jak waluty, ochrona danych osobowych przerodziła się z opcjonalnej zasady w niezbędny imperatyw. Anonimizacja danych wyrasta jako kluczowy strażnik prywatności, umożliwiając bezpieczne korzystanie z dobrodziejstw technologii bez narażania tożsamości jednostek.
Co to jest anonimizacja danych?
Anonimizacja danych to technika stosowana do przekształcania danych osobowych w sposób, który uniemożliwia identyfikację osób, do których się odnoszą. Ten proces pozwala na wykorzystanie danych w badaniach, analizach i decyzjach strategicznych, zabezpieczając jednocześnie prywatność.
Staje się ona więc nie tylko narzędziem ochrony. Ale także kluczem do wykorzystania potencjału ogromnych zbiorów danych, które generujemy każdego dnia, w sposób odpowiedzialny i etyczny
Podróż przez historię
Anonimizacja nie pojawiła się z dnia na dzień; jest wynikiem długiej ewolucji świadomości społecznej i regulacji prawnych. Rozwój ten jest ściśle powiązany z wprowadzeniem kluczowych aktów prawnych, takich jak RODO, które zrewolucjonizowało podejście do ochrony danych w Europie i na świecie.
Historia anonimizacji danych pokazuje ewolucję od prostych metod maskowania tożsamości do zaawansowanych technik kryptograficznych. Ta zmiana odzwierciedla rosnące zrozumienie wartości prywatności oraz konieczność jej ochrony.
Dlaczego to jest tak ważne?
W centrum uwagi znalazła się anonimizacja danych z kilku powodów: od zapewnienia prywatności po zgodność z globalnymi regulacjami ochrony danych. Jest niezbędna nie tylko dla ochrony jednostek, ale także dla umożliwienia bezpiecznej analizy i wykorzystania danych w różnorodnych dziedzinach życia. Anonimizacja stanowi fundament budowania zaufania między użytkownikami a dostawcami usług. Tworzy bezpieczne środowisko dla cyfrowej interakcji i innowacji.

Anonimizacja w praktyce
Polska, podążając ścieżką wytyczoną przez europejskie regulacje, przyjęła anonimizację jako standardową praktykę w ochronie danych. Zrozumienie funkcjonowania anonimizacji w ramach polskiego prawodawstwa jest kluczowe dla organizacji i instytucji dążących do zgodności z RODO i innymi przepisami. W Polsce, proces ten jest nie tylko wymogiem prawnym, ale również elementem kultury korporacyjnej. Promuje transparentność i odpowiedzialność w zarządzaniu danymi osobowymi.
Kluczowe zasady i wyzwania
Anonimizacja danych to nie tylko techniczny proces, ale także szereg wyzwań: od ryzyka reidentyfikacji po znalezienie równowagi między prywatnością a użytecznością danych. Eksploracja tych zagadnień ujawnia złożoność stojącą za anonimizacją i podkreśla potrzebę ciągłego doskonalenia metod. Aby anonimizacja była skuteczna, musi być przemyślana i dostosowana do konkretnego kontekstu, co wymaga nieustannego dialogu między ekspertami z różnych dziedzin.
Dalsze kierunki: co przyniesie przyszłość?
Anonimizacja danych stoi na czele innowacji w ochronie prywatności, ale co przyniesie przyszłość w tej szybko rozwijającej się dziedzinie? Rozwój technologii, takich jak sztuczna inteligencja i uczenie maszynowe, stawia nowe wyzwania dla anonimizacji, jednocześnie oferując nowe możliwości jej doskonalenia. Przyszłość anonimizacji zależeć będzie od naszej zdolności do przewidywania i adaptacji do tych zmian, zachowując przy tym równowagę między innowacją a ochroną prywatności.
Wprowadzenie do Nocturno
Anonimizacja danych to więcej niż proces techniczny; to filozofia ochrony prywatności w cyfrowym świecie. Rozumienie jej podstaw, znaczenia i wyzwań jest kluczowe dla każdego, kto w swojej pracy przetwarza dane osobowe. W miarę jak technologia ewoluuje, tak samo musi ewoluować nasze podejście do anonimizacji, aby zapewnić ochronę prywatności w coraz bardziej połączonym świecie.
W tym kontekście narzędzie takie jak Nocturno, oferujące zaawansowane możliwości anonimizacji danych przy zachowaniu ich użyteczności, staje się nieocenione. Dzięki Nocturno, zespoły mogą efektywnie zarządzać wrażliwymi danymi, zapewniając zgodność z przepisami o ochronie danych i budując zaufanie użytkowników.
Witaj w Wizards! Jesteśmy specjalistami od ochrony danych, dostarczając skuteczne narzędzia do wykrywania, anonimizacji i retencji danych osobowych. Nasze usługi zapewniają pełną zgodność z RODO w zakresie ochrony danych osobowych.
Posiadamy 25-letnie doświadczenie w tworzeniu systemów do obsługi wrażliwych danych w różnych sektorach, wykorzystując najnowsze technologie, takie jak big data i uczenie maszynowe. Jako zaangażowani programiści i współwłaściciele firmy, chcemy odciążyć innych specjalistów od wyzwań związanych z przestrzeganiem RODO. Umożliwiając im tym samym skupienie się na ich własnych zadaniach.
Jeżeli poszukujesz narzędzi do zarządzania danymi osobowymi i wrażliwymi, zapraszamy do kontaktu. Umówmy się na rozmowę. To pierwszy krok, aby Twoja firma mogła uniknąć potencjalnych kar. Skontaktuj się z nami już dziś!
Poznaj konsekwencje z naruszania RODO
Nieprzestrzeganie zasad RODO, takich jak niewłaściwe ograniczenie przechowywania danych (retencji) czy niewłaściwa anonimizacja, prowadząc do naruszenia poufności, może prowadzić do sankcji administracyjnych i nałożenia kar finansowych.
Zgodnie z art. 83 ust. 5 RODO, naruszenia przepisów dotyczących kwestii związanych z zasadami ogólnymi, takimi jak retencja czy minimalizacja, mogą skutkować nałożeniem kary pieniężnej do 20 000 000 EUR, a dla przedsiębiorstw – do 4% całkowitego rocznego światowego obrotu z poprzedniego roku obrotowego. W przypadku obu kwot, zastosowanie znajduje ta wyższa.
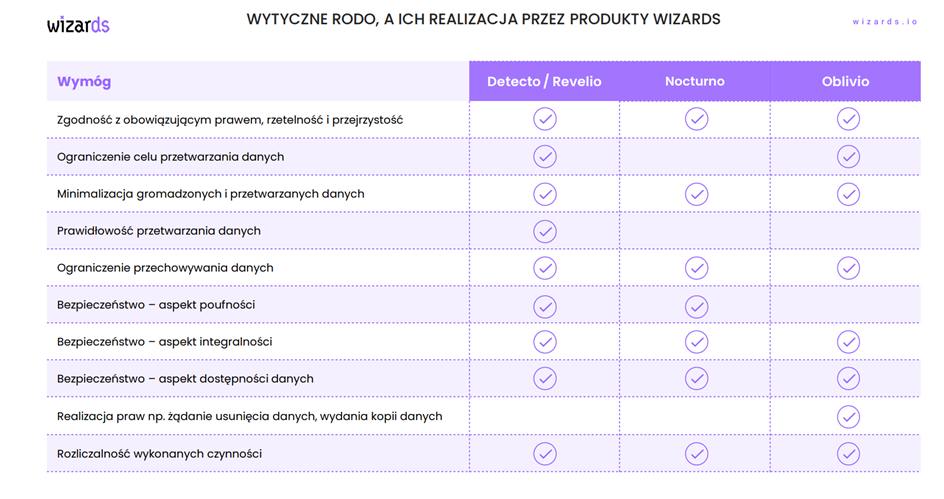
Kluczowe aspekty przetwarzania danych to: zgodność z prawem, rzetelność, przejrzystość, ograniczenie celu i minimalizacja danych, ich prawidłowość i bezpieczeństwo, w tym poufność, integralność i dostępność. Niezbędne jest także uwzględnienie praw, jak usuwanie czy kopiowanie danych, oraz odpowiedzialność za przetwarzanie.
Sprawdź nasze narzędzia
Wybierając Wizards, chronisz swoją firmę przed potencjalnie ogromnymi kosztami wynikającymi z naruszenia przepisów RODO. Można to zobrazować na przykładzie British Airways, które w 2019 roku zostało ukarane karą w wysokości 204 mln euro za naruszenie danych osobowych. Dzięki naszej współpracy, możesz być pewien bezpieczeństwa swoich finansów, przedsiębiorstwa, pracowników i klientów.
- Detecto, system monitorujący dane osobowe i wrażliwe w bazach danych, wspierający procesy anonimizacji i retencji.
- Revelio, skuteczne rozwiązanie do identyfikacji danych osobowych i wrażliwych w dokumentach oraz poczcie elektronicznej, promujące cyfryzację procesów biznesowych.
- Nocturno, zaawansowany system do anonimizacji danych osobowych w systemach informatycznych, zachowujący spójność danych między różnymi systemami.
- Oblivio, dedykowany system do zarządzania retencją danych osobowych w organizacji.
Z Wizards, zapewnisz zgodność z RODO, ochronisz swoją firmę przed kosztownymi karami związanymi z naruszeniem przepisów i zabezpieczysz nie tylko swoje finanse, ale także firmę, pracowników i klientów.
Praktyczne zastosowanie naszych narzędzi
Nasze narzędzia mają realne zastosowanie, które przekłada się na codzienne funkcjonowanie firm. Przedstawiamy poniżej konkretne przykłady.
Detecto. Firma z sektora telekomunikacji korzystała z zaawansowanego rozwiązania klasy ERP jednego z czołowych dostawców. Podczas audytu, IT musiało zlokalizować miejsca w systemie ERP, w którym przechowywane są dane osobowe. Detecto z Wizards przeskanowało bazy danych systemu i dostarczyło raport z lokalizacjami danych osobowych i finansowych.
Revelio. W firmie ubezpieczeniowej, mimo zastosowania różnych narzędzi bezpieczeństwa, doszło do wycieku danych klientów i informacji finansowych. Revelio pomogło zidentyfikować ponad 1000 plików zawierających ponad 100 nazwisk klientów wraz z numerami kont bankowych, zgromadzonych w repozytorium SharePoint i na komputerach osobistych.
Nocturno. Klient korzystał z 20 różnych systemów informatycznych. Dlatego Wizards Nocturno zautomatyzował proces tworzenia środowisk testowych i developerskich, tak, że podczas tworzenia, dane osobowe i wrażliwe były anonimizowane. Co więcej, anonimizacja nie zmienia parametrów jakościowych i ilościowych danych, co pozwoliło na bezpieczne testowanie i rozwój oprogramowania.
Oblivio. Instytucja publiczna przetwarzała dane swoich pracowników. Oblivio pomogło zidentyfikować, które dane powinny być usunięte zgodnie z przepisami o retencji danych. Narzędzie zadbało również o anonimizację danych pracowników, które powinny być usunięte z systemów kadrowych.
Chcesz dowiedzieć się więcej o praktycznym zastosowaniu naszych narzędzi? Skontaktuj się z nami na rozmowę. Mamy dziesiątki innych przykładów!
Modele współpracy
Zabezpiecz swoją firmę jednym ruchem. Odkryj nasze opcje współpracy i umów rozmowę, aby zabezpieczyć swoje przedsiębiorstwo.
Opcje Współpracy:
- Detecto – Identyfikacja danych osobowych w trzech wybranych bazach danych za 10 000 PLN.
- Revelio – Identyfikacja danych osobowych w plikach zasobu współdzielonego (do 100 000 plików) za 10 000 PLN.
- Oblivio – Informacja o ilości danych osobowych, które podlegają retencji, przechowywanych w Twojej bazie (dotyczy 1 procesu, max 3 systemy) za 10 000 PLN.
Oferujemy opcje jednorazowego użytku lub subskrypcji na okres miesiąca lub roku.

Z nami warto!
Przepisy RODO mogą być trudne do zrozumienia i zastosowania. W Wizards, stawiamy na przystępność i skuteczność. Nasze narzędzia Detecto, Revelio, Nocturno i Oblivio, dostosowane do Twoich potrzeb, zapewniają efektywne zarządzanie danymi osobowymi i pełną zgodność z RODO.
Nie pozwól na hamowanie rozwoju Twojej firmy przez strach przed RODO. Dlatego też z nami zyskujesz pewność i bezpieczeństwo, co umożliwia Ci skupienie się na tym, co najważniejsze – Twoim biznesie. Tak więc wybierz Wizards, wybierz jedyną słuszną ochronę. Następnie umów się na rozmowę z nami już dziś i zabezpiecz swoją firmę przed konsekwencjami naruszenia RODO.
Ochrona danych staje się absolutnym priorytetem. Anonimizacja – proces chroniący prywatność osób, których dane przechowujemy – staje się niezbędna. W tym kontekście przedstawiamy narzędzie Nocturno, które umożliwia efektywną anonimizację danych.
Wiodące narzędzie do anonimizacji danych
Nocturno, to zaawansowane narzędzie do anonimizacji. Wykorzystuje rozszerzone słowniki i generatory, zachowując charakterystykę bazy danych. Anonimizuje różne systemy na raz, utrzymując spójność danych. Obsługuje równoległe przetwarzanie i cache, a także anonimizuje dane osobowe i inne wrażliwe dane, np. finansowe.
Dla kogo jest Nocturno?
Nocturno jest idealne dla zespołów, które planują anonimizować dane. Obejmuje to zespoły tworzące, rozwijające i utrzymujące systemy z wrażliwymi danymi. Jest również użyteczne dla procesu testowania oprogramowania i przekazywania zanonimizowanych raportów do innych systemów. Nocturno integruje się z naszym innym produktem – Detecto, który pomaga łatwo znaleźć wrażliwe dane.
Jak działa Nocturno?
Nocturno pozwala zadeklarować reguły dla wartości do anonimizacji i zawiera wbudowane generatory najczęściej występujących typów danych. Bierze pod uwagę złożoność nowoczesnych systemów informatycznych, co pozwala na dostosowanie do struktury bazy danych. Zapewnia spójność zanonimizowanych danych między różnymi bazami danych. Obsługuje wiele typów baz danych i generuje dane w różnych językach.
Kluczowe funkcje Nocturno
Nocturno deklaruje reguły dla wartości podlegających anonimizacji. Generuje najczęściej występujące typy danych. Dostosowuje się do złożoności nowoczesnych systemów informatycznych, dopasowując się do struktury bazy danych. Zapewnia spójność zanonimizowanych danych w różnych bazach danych. Obsługuje wiele typów bazy danych (MySQL, DB2, SQL Server, Oracle, PostgreSQL). Generuje różne typy danych, takie jak imię i nazwisko, PESEL, NIP, REGON, adres. Generuje dane w różnych językach.
Proces anonimizacji danych
Pierwszym krokiem do przygotowania firmy do wdrożenia Nocturno jest zrozumienie, jakie dane są przechowywane i gdzie. Trzeba przeprowadzić audyt wszystkich systemów i baz danych, aby zidentyfikować, które dane są wrażliwe i wymagają anonimizacji.
Następnie warto zidentyfikować wszystkie zespoły, które będą korzystać z Nocturno. Wszystkim tym zespołom powinno się przekazać informacje o nowym narzędziu i zapewnić odpowiednie szkolenia.
Przyda się także przygotować plan testów. Wreszcie, firma powinna być gotowa na wprowadzenie zmian w swoich systemach.

Korzyści z Nocturno
Jakość: Znacząco, anonimizacja nie wpływa na jakość danych, co nie tylko pomaga, ale wręcz gwarantuje utrzymanie wysokiej jakości procesów developmentu i testów.
Automatyzacja: Interesującym aspektem jest to, że Nocturno jest kompatybilne z narzędziami CI/CD, takimi jak Jenkins, co pozwala na skuteczną automatyzację procesu anonimizacji.
Wydajność: Dzięki niezwykle wysokiej wydajności Nocturno, proces anonimizacji odbywa się tak sprawnie, że staje się prawie niewidoczny dla funkcjonowania organizacji.
Wsparcie testów: Co więcej, anonimizacja danych umożliwia testowanie oprogramowania bez konieczności operowania na rzeczywistych danych osobowych.
Bezpieczeństwo: Innym istotnym atutem jest to, że Nocturno pozwala na efektywne ograniczenie dostępu do danych produkcyjnych, co znacząco podnosi poziom bezpieczeństwa.
Wygoda: Na koniec, dzięki automatycznej anonimizacji, możliwe staje się łatwe odtworzenie bazy danych do jej poprzedniej wersji, co jest niezwykle wygodne w codziennym funkcjonowaniu.
Integracja z Detecto
Nocturno integruje się z Detecto, narzędziem pomagającym w łatwym wyszukiwaniu wrażliwych danych w różnych systemach i bazach danych.
Anonimizacja danych z Nocturno
Anonimizacja danych jest kluczowa w dzisiejszym cyfrowym świecie. Nocturno umożliwia efektywne i bezpieczne anonimizowanie danych, chroniąc prywatność użytkowników i zgodność z prawem. Choć wymaga to pewnego wysiłku i czasu, korzyści z anonimizacji danych są znaczne. W erze cyfrowej, gdzie prywatność danych jest kluczowa, Nocturno oferuje niezawodne i efektywne rozwiązanie do anonimizacji danych.
RODO to skrót od Rozporządzenia Ogólnego o Ochronie Danych Osobowych, czyli unijnego aktu prawnego, który reguluje ochronę prywatności i przetwarzanie danych osobowych w Europie. Wprowadzono to rozporządzenie 25 maja 2018 roku, które zastąpiło poprzednią dyrektywę o ochronie danych osobowych.
RODO nakłada na firmy i organizacje obowiązek przestrzegania szeregu przepisów dotyczących przetwarzania danych osobowych, w tym zbierania, przetwarzania, przechowywania i usuwania tych informacji. Celem RODO jest zapewnienie ochrony prywatności i uniknięcie nadużyć w stosunku do danych osobowych.
Naruszenie tych przepisów może skutkować poważnymi sankcjami nie tylko reputacyjnymi ale i drakońskimi karami finansowymi. Warto również pamiętać, że każda firma lub organizacja, która przetwarza dane osobowe w Unii Europejskiej musi przestrzegać RODO.
Jaki szereg przepisów nakłada RODO na firmy?
RODO wymaga od firm i organizacji, które przetwarzają dane osobowe, aby poinformowały zainteresowane osoby o celach przetwarzania tych danych oraz o prawach jakie im przysługują. Osoby te mają również prawo dostępu do swoich danych oraz prawo do ich poprawiania, usuwania i przenoszenia. RODO nakłada na firmy i organizacje szereg przepisów, których przestrzeganie jest obowiązkowe.
- Zasada przejrzystości – firmy i organizacje muszą informować osoby, których dane dotyczą, o celach przetwarzania ich danych jak i o tym, kto jest administratorem ich danych,
- Zasada ograniczenia celu – dane osobowe powinny być zbierane i przetwarzane tylko wtedy, gdy jest to niezbędne do realizacji określonych celów,
- Zasada minimalizacji danych – firmy i organizacje powinny zbierać i przetwarzać tylko te dane osobowe, które są niezbędne do realizacji określonych celów,
- Zasada poprawności danych – firmy i organizacje muszą dbać o to, aby dane osobowe były aktualne i poprawne,
- Zasada ograniczenia przechowywania danych – dane osobowe nie powinny być przechowywane dłużej niż jest to niezbędne,
- Zasada poufności i bezpieczeństwa – firmy i organizacje muszą chronić dane osobowe przed nieautoryzowanym dostępem, utratą lub uszkodzeniem.
Firma musi również prowadzić dokładną dokumentację dotyczącą przetwarzania danych osobowych. W tym rejestry czynności przetwarzania oraz ewidencję naruszeń ochrony danych osobowych. Dodatkowo, musi wyznaczyć Inspektora Ochrony Danych (IOD). Odpowiedzialny on będzie za monitorowanie przestrzegania zasad ochrony danych osobowych i kontakt z organem nadzorczym.

Jakie są kary za złamanie RODO?
RODO przewiduje wysokie kary finansowe za naruszenie przepisów. Wysokość kar zależy od rodzaju naruszenia i okoliczności sprawy. Można ukarać firmę lub organizację za m.in.:
- naruszenie zasad przetwarzania danych osobowych. Kara może wynosić do 20 milionów euro lub 4% globalnego rocznego obrotu firmy (w zależności od tego, która kwota jest wyższa);
- naruszenie obowiązków dotyczących powiadamiania o naruszeniu ochrony danych osobowych. Kara może wynosić do 10 milionów euro lub 2% globalnego rocznego obrotu firmy (w zależności od tego, która kwota jest wyższa);
- naruszenie praw osób, których dane dotyczą. Kara może wynosić do 20 milionów euro lub 4% globalnego rocznego obrotu firmy (w zależności od tego, która kwota jest wyższa).
Największe kary nałożone za złamanie RODO
W 2019 roku francuski organ nadzorczy nałożył na Google karę w wysokości 50 milionów euro za naruszenie zasad RODO. Firma nie dostarczała wystarczających informacji na temat sposobu przetwarzania danych oraz nie uzyskiwała odpowiedniego zgody na przetwarzanie danych osobowych użytkowników.
W 2020 roku brytyjski organ nadzorczy nałożył na British Airways karę w wysokości 183 milionów funtów za naruszenie RODO. Firma nie zabezpieczyła odpowiednio swojej strony internetowej, co umożliwiło cyberatak i wyciek danych osobowych klientów.
W 2021 roku niemiecki organ nadzorczy nałożył na H&M karę w wysokości 35,3 milionów euro za naruszenie prywatności pracowników. Firma zbierała i przetwarzała nielegalnie dane osobowe swoich pracowników w celu monitorowania ich życia prywatnego i życia rodzinnego.
Sprawdź nasze produkty i ochroń swoją firmę
Wdrażając Nocturo, Oblivio i Detecto – zwiększysz bezpieczeństwo wrażliwych danych w swojej organizacji oraz zgodność RODO.
Detecto: Narzędzie do wykrywania danych osobowych oraz wrażliwych w bazach danych,
Nocturno: Narzędzie do anonimizacji danych osobowych w systemach informatycznych,
Oblivio: System do retencji danych osobowych i zarządzania danymi osobowymi w organizacji.
Skontaktuj się z nami, a zabezpieczymy Twoją firmę przed niepożądanymI karami finansowymi. Nasze produkty spełniają wszystkie zasady nakładane przez RODO.
Co muszę zrobić, aby moja firma przestrzegała przepisów RODO?
Aby wdrożyć przepisy RODO w firmie, musisz przede wszystkim:
- Określić cele przetwarzania danych osobowych: musisz określić, w jaki sposób będziesz przetwarzał dane osobowe i jakie cele będą tym kierować.
- Zidentyfikować podstawę prawą przetwarzania danych osobowych: musisz określić, jakie przepisy prawa umożliwiają przetwarzanie danych osobowych w Twojej firmie.
- Przygotować politykę prywatności i informować o niej klientów: musisz przygotować politykę prywatności. Która określa, jakie dane są zbierane, w jaki sposób są przetwarzane. Kto jest odpowiedzialny za ich przetwarzanie, jakie są prawa klientów związane z ich danymi osobowymi, itp. Następnie musisz upewnić się, że klienci są informowani o polityce prywatności przed udostępnieniem swoich danych osobowych.
- Zapewnić bezpieczeństwo przetwarzania danych osobowych: musisz zabezpieczyć dane osobowe przed utratą, zniszczeniem lub nieuprawnionym dostępem. Musisz wykorzystać odpowiednie środki techniczne i organizacyjne, takie jak szyfrowanie, regularne tworzenie kopii zapasowych, autoryzacja dostępu, itp.
- Wdrożyć procedury przetwarzania danych osobowych: musisz wprowadzić procedury przetwarzania danych osobowych, które będą przestrzegać przepisów RODO. Określić, jakie kroki należy podjąć w przypadku naruszenia ochrony danych osobowych.
- Szkolić pracowników: musisz przeszkolić pracowników na temat przepisów RODO i wdrożonych procedur przetwarzania danych osobowych.
Pamiętaj, że przestrzeganie przepisów RODO to proces ciągły i wymaga stałego monitorowania i aktualizacji procedur.

Borykasz się
z problemem zwiększonego ryzyka wycieku
danych osobowych podczas pracy zdalnej?
Chcesz ograniczyć dostęp do wrażliwych
danych w swojej firmie?
Chcesz dowiedzieć się więcej na temat
procesu anonimizacji danych?
A może zastanawiasz się, czy proces
anonimizacji, który masz wdrożony w swojej firmie można usprawnić?
Jeśli tak, ten artykuł jest dla Ciebie. Wspólnie z Mirkiem Gumularzem, Radcą Prawnym zajmującym się zagadnieniami związanymi z RODO, postanowiliśmy poruszyć temat poprawnej, szybkiej i bezpiecznej anonimizacji danych osobowych.
Z artykułu dowiesz się m.in.:
- Jakie są różnice między anonimizacją a pseudonimizacją?
- Dlaczego warto anonimizować dane z punktu widzenia IT, compliance, czy biznesu?
- Jakie są korzyści i ryzyka związane z anonimizacją?
Zapraszamy do lektury!
Artur Żórawski, Founder&CTO Wizards
i Mirosław Gumularz, Radca Prawny w GKK Gumularz Kozik
Zapraszamy,
Artur Żórawski, Founder i CTO Wizadrs
Architekt IT z ponad 20 letnim stażem, autor pomysłów na rozwiązania IT do detekcji, anonimizacji i retencji danych.
i
dr Mirosław Gumularz, Radca Prawny GKK Gumularz Kozik
Audytor wewnętrzny systemu zarządzania bezpieczeństwem informacji wg normy ISO 27001:2013. Członek Grupy Roboczej ds. Ochrony Danych Osobowych przy Ministerstwie Cyfryzacji.
———————————
Anonimizacja a pseudonimizacja
Mirosław Gumularz (MG): W ostatnim artykule mówiliśmy sporo na temat zmian, które zaszły wraz z RODO w podejściu do zapewnienia zgodności z ochroną danych. Jednym ze sposobów, w jaki możemy o dane dbać jest anonimizacja, lub pseudonimizacja danych, czyli odpowiednio: zerwanie lub ograniczenie identyfikowalności osób fizycznych.
Mówiąc o anonimizacji i pseudonimizacji widzę duży problem w rozróżnieniu obu pojęć. Wiele osób uważa, że zrealizowało wymogi co do ochrony danych (np. ich usuwania), bo zanonimizowało dane. W praktyce okazuje się często, że to nie jest anonimizacja, tylko pseudonimizacja, czyli nie zerwanie, a odwracalne ograniczenie identyfikowalności, ponieważ cały czas istnieje jakiś rodzaj powiązania (chociażby poprzez zebranie dodatkowych danych ze źródeł publicznie dostępnych np. strony rejestrów publicznych, takich jak np. geoportal). Nie wiem, jak to z Waszej perspektywy wygląda, osób technicznych?
Artur Żórawski (AŻ): Mam podobne obserwacje. Jest to związane pewnie z tym, że przeprowadzenie anonimizacji przy zachowaniu odpowiedniej jakości charakterystyki bazy, nie jest taką banalną sprawą. Podstawową wartością anonimizacji jest jej nieodwracalność. Jeśli udało się ją osiągnąć, to to oznacza właśnie dobrze zrobioną anonimizację. Możemy mieszać, maskować, ale rezultat powinien być jeden: brak możliwości zidentyfikowania konkretnej osoby. Z pseudonimizacją jest inaczej. Pseudonimizacja zakłada posiadanie klucza, za pomocą którego możemy odwrócić anonimizację i odzyskać dane. W efekcie nie tracąc ich.
MG: Tak, dokładnie. To, na co warto zwrócić uwagę to fakt, że od strony prawnej nie ma czegoś takiego, jak wymóg anonimizacji/pseudonimizacji. Są to narzędzia do realizacji określonych celów/wymogów np. bezpieczeństwa, czy ograniczenia czasowego przechowywania danych. Oba pojęcia dotyczą identyfikacji osoby fizycznej, czyli najogólniej rzecz ujmując – powiązania informacji z wyodrębnioną osobą fizyczną.
- Anonimizacja –
służy zerwaniu powiązania pomiędzy informacją a wyodrębnioną osobą
fizyczną. Anonimizacja to de facto zmiana informacji i alternatywa dla
fizycznego usuwania danych. Informacja zanonimizowana nie jest już daną
osobową. Oczywiście prawidłowo zanonimizowana informacja.
- Natomiast
pseudonimizacja służy ograniczeniu powiązania
informacji z wyodrębnioną osobą fizyczną. RODO definiuje pseuodonimizację jako:
“Przetworzenie danych osobowych w taki
sposób, by nie można ich było już przypisać konkretnej osobie, której dane
dotyczą, bez użycia dodatkowych informacji, pod warunkiem, że takie dodatkowe
informacje są przechowywane osobno i są objęte środkami technicznymi oraz
organizacyjnymi uniemożliwiającymi ich przypisanie zidentyfikowanej, lub
możliwej do zidentyfikowania osobie fizycznej.”
W praktyce, dane speudonimizowane są cały czas danymi osobowymi. Oznacza to, że przetwarzając je, musimy zapewnić realizację wszystkich wymogów, o których mówiliśmy w pierwszym tekście, m.in. co do czasu przetwarzania danych, ograniczenia celu i minimalizacji.
Nie mniej RODO traktuje pseudonimizację przede wszystkim jako środek do realizacji wymogu bezpieczeństwa według prostego rozumowania: jak wyciekną dane pseudonimizowane, to ryzyko dla osób fizycznych jest mniejsze, bo identyfikacja będzie utrudniona, lub wręcz niemożliwa (dla uzyskującego dostęp do części danych bez tego “klucza”, o którym mowa w definicji).
Korzyści wynikające z anonimizacji
- Rozwiązanie problemu ograniczenia celu przetwarzania
MG: Wiemy już, jaka jest różnica między anonimizacją a pseudonimizacją. Zastanówmy się teraz, po co w ogóle anonimizować dane? Z punktu widzenia RODO anonimizacja ułatwia przede wszystkim „obejście” problemu celu przetwarzania. To z pozoru bardzo ogólny wymóg, który ma bardzo konkretne konsekwencje techniczne. Jeśli w trakcie przetwarzania chcemy zmienić cel przetwarzania, (np. wykorzystać te dane do rozwoju „uczenia” sztucznej inteligencji) to możemy w tym zakresie mieć kłopot z zalegalizowaniem tej zmiany celu. Wprawdzie RODO tego nie wyklucza, ale zawiera szereg obostrzeń m.in. obowiązek informowania o tym osób, których dane dotyczą. Anonimizacja rozwiązuje ten problem. Dane anonimowe nie podlegają RODO.
AŻ: Tak, masz rację. Jakiś czas temu braliśmy udział w projekcie z zakresu sztucznej inteligencji i uczenia maszynowego, w ramach których wnioskowaliśmy i uczyliśmy algorytmy w oparciu o zbiór danych. Jednym z wyzwań była anonimizacja tego zbioru w taki sposób, że dane osób i w efekcie cały zbiór miały zachowywać charakterystykę i swoją tożsamość. Dane miały być w pełni wartościowe. Musieliśmy wymyśleć, jak to zrobić. Biorąc wszystkie te wszystkie wymogi pod uwagę można zażartować, że najlepiej tak naprawdę to tych danych nie mieć, ale w biznesie jest to praktycznie niemożliwe.
- Ograniczenie czasu przetwarzania
MG: Masz rację. Trzeba pamiętać że sensie prawnym anonimizacja jest równoznaczna z fizycznym usunięciem danych. W obu przypadkach nie mamy danych osobowych (oczywiście o ile ten proces nastąpił w sposób prawidłowy). Dlatego anonimizacja ma także znaczenie przy realizacji wymogu ograniczenia czasowego przetwarzania, czyli jednego z fundamentów RODO. W tym wypadku anonimizacja oznacza wykonanie pewnego procesu, który powoduje, że informacja, która wcześniej dotyczyła zidentyfikowanej, lub możliwej do identyfikacji osoby, teraz już jej nie dotyczy. Stała się daną anonimową. Dlatego anonimizacja (jako metoda przetworzenia informacji) może być pomocna, gdy fizyczne usuwanie danych zgodnie z terminami przyjętymi w wewnętrznych politykach organizacji nie jest faktycznie możliwe (np. ze względu na realizację pomiędzy bazami danych).
- Realizacja wymogów bezpieczeństwa
MG: Anonimizacja pozwala zrealizować także wymogi bezpieczeństwa w zakresie poufności danych. To jest tym bardziej istotne w przypadku:
- pracy na urządzeniach mobilnych, które można zgubić, lub które mogą zostać ukradzione,
- lub pracy zdalnej, podczas której dane mogą zostać wykradzione przez np. niezabezpieczoną sieć.
Anonimizując dane, ograniczamy ryzyko ich wycieku. Anonimizacja spowoduje, że osoba niepożądana, która zyska dostęp do baz danych, nie zyska tym samym dostępu do danych osobowych, a jedynie do ich zanonimizowanej wersji. Jest to szczególnie gorący temat w kontekście obecnej pandemii COVID-19, który wymusił na firmach wysłanie zdecydowanie większej ilości pracowników na pracę zdalną, niż to było do tej pory. Praca zdalna na danych anonimowych nie rodzi ryzyka związanego z naruszeniem RODO.
AŻ: Anonimizacja z punktu widzenia programisty, architekta w takim przypadku daje możliwość spokojnego skupienia się na tym, na czym znamy się najlepiej – programowaniu i projektowaniu.
Ja widzę jeszcze kilka korzyści z punktu widzenia IT.
Systemy informatyczne nie lubią usuwania danych. Większość systemów preferuje gromadzenie dużych ilości danych, ponieważ w niektórych przypadkach fizyczne ich usunięcie może wpłynąć na efektywność systemu. Konieczność usuwania pojawia się w momencie, w którym użytkownik zażąda usunięcia jego danych osobowych, z których my akurat korzystamy. Z tego też względu tam, gdzie można oczywiście usuwamy te dane. W miejscach gdzie byłoby to kłopotliwe, dane ulegają anonimizacji. Oznacza to, że pod względem RODO dane znikają, ale nie są usuwane fizycznie.
Miejscem, gdzie anonimizacja jest jeszcze stosowana w kontekście systemów informatycznych są testy. Wiemy, że zapewnienie odpowiedniej jakości testów też jest bardzo ważne. Przygotowanie testowych danych osobowych często jest trudne ze względu na ilość oraz charakter tych danych. W tym przypadku można wykorzystać te dane produkcyjne, które przeszły przez proces anonimizacji, dzięki czemu przestają podlegać RODO. Dzięki temu systemy mogą być testowane nie tylko pod względem funkcjonalności, ale mogą być również testowane pod kątem obciążeń – kontroli, czy dany system informatyczny będzie w stanie wytrzymać ruch i obciążenie systemu przez wszystkich użytkowników. Jest to ważne bo przecież nikt nie podpisuje zgód na wykorzystanie jego danych osobowych do testowania systemu.
- Wykorzystanie anonimizacji w biznesie
AŻ: Jeżeli chodzi o korzyści biznesowe, to jest ich kilka. Na przykład jedna firma prosi inną firmę o rozwój swojego systemu i w związku z tym dochodzi do przekazania danych osobowych. Ze względu na to, że system już istnieje trzeba go utrzymywać i w takim przypadku może dojść do przekroczenia danych osobowych między dwoma organizacjami. Dzięki anonimizacji baz danych będziemy w stanie przekazać jakościowe dane, lecz bez prawdziwych danych osobowych.
Należy pamiętać, że żadna firma nie są samotną wyspą, dlatego w dzisiejszym biznesie dane dość swobodnie pływają pomiędzy podmiotami bez żadnych dodatkowych umów, czy obostrzeń. Mimo tego świadomość na temat danych osobowych w organizacji jest niska. Z doświadczenia mogę powiedzieć, że jedną z wątpliwości, którą często słyszę podczas spotkań w związku z wdrożeniem narzędzi anonimizacji danych jest brak wiedzy na temat przechowywania i przetwarzania danych osobowych. Dopiero gdy poznamy ten proces, możemy się zastanawiać się nad tym, co powinniśmy zmienić w systemach informatycznych i jakie procedury informatyczne oraz narzędzia powinny zostać wdrożone.
Ryzyka związane z anonimizacją
MG: Anonimizacja to korzyści, ale również ryzyka.Trzeba pamiętać, że proces anonimizacji może rodzić ryzyko dla ludzi, którego źródłem jest błąd i brak zerwania powiązania informacji z osobą fizyczną. W zakresie mierzenia tego ryzyka polecam dwa dokumenty:
- Opinia Grupy Roboczej art. 29 6/2013 dostępna pod linkiem: https://archiwum.giodo.gov.pl/pl/1520167/6944
- Rekomendacje ICO https://ico.org.uk/media/1061/anonymisation-code.pdf
Oba dokumenty zawierają przykłady błędów, dobre praktyki oraz kryteria szacowania ryzyka, którego źródłem może być nieprawidłowa anonimizacja. Więcej o tych dokumentach będziemy mówić również na webinarium.
W obu dokumentach podkreśla się, że granica pomiędzy danymi prawidłowo zanonimizowanymi jest płynna. Zresztą RODO wskazuje, że te same informacje w zależności od kontekstu (i możliwości zestawienia z innymi danymi przez dany podmiot) mogą być danymi anonimowymi, lub danymi osobowymi.
Zgodnie z motywem 26 rodo:
„(…) aby stwierdzić, czy dana osoba fizyczna jest możliwa do zidentyfikowania, należy wziąć pod uwagę wszelkie rozsądnie prawdopodobne sposoby (w tym wyodrębnienie wpisów dotyczących tej samej osoby), w stosunku do których istnieje uzasadnione prawdopodobieństwo, iż zostaną wykorzystane przez administratora lub inną osobę w celu bezpośredniego lub pośredniego zidentyfikowania osoby fizycznej. Aby stwierdzić, czy dany sposób może być z uzasadnionym prawdopodobieństwem wykorzystany do zidentyfikowania danej osoby, należy wziąć pod uwagę wszelkie obiektywne czynniki, takie jak koszt i czas potrzebne do jej zidentyfikowania, oraz uwzględnić technologię dostępną w momencie przetwarzania danych, jak i postęp technologiczny. Zasady ochrony danych nie powinny więc mieć zastosowania do informacji anonimowych, czyli informacji, które nie wiążą się ze zidentyfikowaną lub możliwą do zidentyfikowania osobą fizyczną, ani do danych osobowych zanonimizowanych w taki sposób, że osób, których dane dotyczą, w ogóle nie można zidentyfikować lub już nie można zidentyfikować”.
Powyższy cytat oznacza, że pojęcie danych osobowych obejmuje informacje o różnym stopniu powiązania z wyodrębnioną osobą fizyczną, a granica pomiędzy danymi osobowymi oraz danymi anonimowymi jest często trudna do wytyczenia.
W związku z tym można wyróżnić następujące sytuacje:
- Identyfikacja jest możliwa w oparciu o dane, którymi dysponuje administrator, nawet jeżeli identyfikacja wymaga ich zestawienia (np. dane w różnych bazach danych, przetwarzane lokalnie na urządzeniach, w usługach chmurowych). W tej kategorii mieszczą się także dane spseudonimizowane.
- Identyfikacja jest utrudniona (np. wymaga pozyskania dodatkowych danych), ale możliwa bez nadmiernych trudności.
- Zidentyfikowanie osoby fizycznej chociaż potencjalnie możliwe, jest nadmiernie uciążliwe (biorąc pod uwagę kryteria z motywu 26 RODO).
- Zidentyfikowanie osoby fizycznej nie jest możliwe nawet po uzyskaniu dodatkowych informacji (biorąc pod uwagę kryteria z motywu 26 rodo)
Oznacza to, że ustalenie czy określona informacja jest daną osobową wymaga oceny. Jak wskazują przytoczone dokumenty należy ocenić ryzyko, którego źródłem jest błąd na etapie anonimizacji prowadzący do re-identyfikacji. Chcąc oszacować to ryzyko należy:
- znać kontekst przetwarzania m.in. powiązania pomiędzy informacjami przetwarzanymi m.in. w różnych systemach obsługujących różne bazy danych;
- ocenić wagę takiego ryzyka (czyli upraszczając – jakie szkody dla ludzi wywoła wystąpienie ryzyka);
- ocenić prawdopodobieństwo ryzyka.
Niezwykle trudne jest oszacowanie prawdopodobieństwa ryzyka re-identyfikacji. Jeśli chcemy to zrobić idąc w ślad za rekomendacjami, warto posłużyć się testem tzw. zmotywowanego intruza. Na czym on polega?
Test zmotywowanego intruza
MG: Polega on głównie na rozważeniu, czy „intruz” byłby w stanie dokonać re-identyfikacji, gdyby był do tego zmotywowany. Podejście to zakłada, że „zmotywowany intruz” jest kompetentny i ma dostęp do zasobów współmiernych do motywacji, jaką może mieć do ponownej identyfikacji.
Niektóre rodzaje danych będą bardziej atrakcyjne dla „zmotywowanego intruza” niż inne. Na przykład intruz może być bardziej zmotywowany do re-identyfikacji danych osobowych, jeśli takie dane:
- mają znaczącą wartość handlową (w tym na czarnym rynku lub poza Unią Europejską) i dlatego można je kupować i sprzedawać w celu uzyskania korzyści finansowych;
- mogą być wykorzystywane do celów egzekwowania prawa lub wywiadowczych;
- mogą ujawniać godne uwagi informacje o osobach publicznych;
- mogą być wykorzystywane do celów politycznych lub aktywistycznych (np. jako część kampanii przeciwko konkretnej organizacji lub osoby);
- mogą być wykorzystywane z osobistych powodów opartych na złych intencjach (np. prześladowania, nękania, zastraszania).
- mogą wzbudzić ciekawość.
AŻ: Tutaj poruszyłeś też bardzo ważny temat. Bezpieczeństwo danych to nie tylko RODO. Dane finansowe, tajemnice firmowe to są wszystko kategorie danych, które chcemy ochronić przed osobami nieuprawnionymi. W tym kontekście zabezpieczenie danych za pomocą anonimizacji jest znacznie szersze. Niektóre z naszych projektów bezpośrednio dotyczyły anonimizacji systemów finansowych i przetargowych, gdzie kwestie związane z danymi osobowymi praktycznie nie występowały, aczkolwiek zabezpieczenie danych finansowych oraz informacji powierzonych przez firmy trzecie było kluczowe dla działania całej organizacji.
Jeśli zainteresował Was temat anonimizacji oraz warunków, jakie muszą być spełnione, żeby mówić o dobrej jakości anonimizacji, zerknijcie również na jeden z moich wcześniejszych artykułów: https://wizards.io/2020/02/anonimizacja/
Znajdziecie tam m.in. rozwinięcie każdego z pojęć wykorzystanych przeze mnie w poniższym wykresie:

———————————————
Odpowiadasz za techniczny lub prawny aspekt ochrony danych osobowych, ochronę bezpieczeństwa danych osobowych lub wrażliwych w swojej organizacji? A może w obszarze, którym się zajmujesz?
Przez kolejne 2 tygodnie będziemy publikować na blogu Wizards nowe artykuły z cyklu RODO w IT, z których dowiesz się kolejno:
- jak poradzić sobie z wyzwaniem skutecznej retencji danych osobowych
- jak realizować projekty z zakresu sztucznej inteligencji w kontekście wymogów RODO
Masz dodatkowe pytania, chcesz wymienić się doświadczeniami, dowiedzieć się więcej o anonimizacji, detekcji i retencji danych osobowych, cykl życia produktów IT w kontekście RODO, w tym privacy by design, a także posłuchać o ciekawych case studies związanych np. z definicją danych osobowych, lub kolejnych etapach wdrażania RODO w Polsce.
Zapisz się już dziś na nasz webinar RODO W IT.
Śledź nasz profil na LinkedIn.
Do usłyszenia!
Artur i Mirek

Niedługo minie dwadzieścia lat od momentu, kiedy dołączyłem do świata IT. Przez ten okres obserwowałem, jak zmienia się to środowisko, jak rozwijają się procesy wytwórcze i jakie nowe narzędzia są wykorzystywane. Z czasem wiele procesów, m.in. powtarzalne zadania, ulegało automatyzacji. Firmy wdrażały Continuous Integration i Continuous Delivery. Wszystkiemu przewodziła jedna myśl: pozwolić twórcom oprogramowania skupić się na rozwoju systemów i biznesie.
Wejście RODO
Wejście RODO wstrząsnęło światem IT i narzuciło nowe reguły gry. Proces wytwórczy stał się bardziej skomplikowany, operowanie na danych osobowych stało się dużym ryzykiem, które trzeba było zaadresować. Pracując w software house widzieliśmy te problemy wyraźnie, ponieważ występowały w każdym z naszych projektów. Teoretycznie byliśmy przygotowani na wejście RODO. Byliśmy po odpowiednich kursach, firma zbroiła się w dokumenty i rejestry. W praktyce okazało się, że obostrzenia prawne i niepewność związana z wejściem w życie tego rozporządzenia, wpłynęły na naszą codzienną pracę. Mój sen o developmencie bez przeszkód, gdzie możemy skupić się tylko na produkcji oprogramowania, prysnął.
Krótko po wdrożeniu RODO rozpoczęło się szukanie rozwiązań. Narzędzia, które udawało nam się znaleźć, nie odpowiadały na nasze potrzeby projektowe, ponieważ na co dzień rozwijaliśmy całe, zintegrowane, tworzone w różnych technologiach ekosystemy wymieniające się danymi osobowymi. Obsługa każdego przypadku, ręcznie i z osobna, była dla mnie nie do przyjęcia. Czułem się tak, jakbym cofnął się o dwie dekady.
Zmiana status quo
Ostatecznie w firmie wyłoniła się grupa ludzi, która postawiła sobie za cel zmianę status quo. Wiedzieliśmy, czego potrzebujemy i jak możemy ten plan zrealizować. Z takim wyzwaniem nigdy wcześniej się nie mierzyliśmy. Wspólnie jednak udało nam się stworzyć zestaw narzędzi, który był dla nas wybawieniem.
Anonimizacja danych
Zaczęliśmy od anonimizacji danych na środowiskach testowych. Stworzyliśmy narzędzie, które było w stanie obsłużyć wiele aplikacji na raz, wziąć pod uwagę polską specyfikę i wykonać swoją pracę wydajnie.
Wytworzone rozwiązanie miało obsługiwać wszystkie nasze projekty, dlatego priorytetem była wysoka konfigurowalność i możliwość dostosowania do różnych wymogów. Anonimizację włączyliśmy w procesy Continuous Integration i szybko wdrożyliśmy je w naszych projektach. Okazało się, że te najbardziej bolesne dla nas aspekty RODO są obsługiwane automatycznie i przestały spędzać sen z powiek zespołowi developerskiemu. Zupełnie tak, jakby ten obszar RODO przestał nas dotyczyć.
Retencja danych osobowych
Kolejnym krokiem była retencja danych osobowych, która jest niezbędna w prawie każdym systemie. Zadbanie o ten aspekt w pojedynczej aplikacji jest łatwe. Wykonanie retencji danych w dziesięciu zintegrowanych systemach jest znacznie trudniejsze, a przy stu – już praktycznie niemożliwe. Było dla nas jasne, że nie chcemy powtarzać tej samej funkcjonalności we wszystkich systemach, które wytwarzamy. W ten sposób narodziło się kolejne narzędzie, które zdejmowało z nas kolejny problem.
Wszystko wróciło na dobre tory, tak jak sobie wymarzyłem. Na szczęście RODO okazało się być jedynie wybojem na drodze w naszych projektach.
Wizards
Z tą też myślą założyliśmy startup. Doszliśmy do wniosku, że problemy, z którymi borykaliśmy się do tej pory dotyczą wielu zespołów developerskich, a my mamy klucz do ich rozwiązania. Dlatego też postanowiliśmy stworzyć nocturno i oblivio, o których już wkrótce więcej przeczytacie m.in. na naszym firmowym profilu Wizards.
Artur Żórawski, Founder&CTO Wizards

Mało kogo ominęły przepastne artykuły na temat RODO i przeróżnych, często przerażających sankcji za jej nieprzestrzeganie. Niewielu za to zagłębia się w takie istotne szczegóły, jak znacznie anonimizacji czy retencji, które pozwalają uniknąć tych wyżej wspomnianych sankcji oraz znacząco ułatwić pracę deweloperów. Z tego też względu postanowiliśmy w przystępny sposób wyjaśnić, czym są anonimizacja i retencja danych osobowych oraz pokazać, dlaczego ich właściwe wykonanie ma takie znaczenie w procesie wytwarzania oprogramowania. Dzisiaj na warsztat bierzemy anonimizację.
Czym jest anonimizacja?
Anonimizacja to proces pozwalający na trwałe usunięcie powiązań między danymi osobowymi, a osobą, której dotyczą. W ten sposób informacje, które przed anonimizacją były danymi osobowymi, przestają nimi być.
Jak to wygląda w praktyce?
Powyższa definicja staje się mniej zagmatwana jeśli wesprzemy ją przykładem. Wyobraźmy sobie np. Supermana – komiksowego bohatera pochodzącego z Kryptonu, który chce ukryć swoją tożsamość i wtopić się w tłum.
| Nazwa | Superman |
| Zawód | Bohater |
| Pochodzenie | Krypton |
Podczas procesu anonimizacji Superman wchodzi do budki telefonicznej, zakłada okulary, tweedowy garnitur i staje się w tym momencie Clarkiem Kentem, reporterem z Kansas.
| Nazwa | Clark Kent |
| Zawód | Reporter |
| Pochodzenie | Kansas, USA |
W procesie anonimizacji dane Supermana zamieniły się na dane Clarka Kenta, co więcej nie ma żadnego powiązania między tymi dwiema osobami. To dane fikcyjne, które mogą być bezpiecznie wykorzystywane np. na środowiskach testowych.
Powyższy przykład obrazuje, na czym polega sam proces anonimizacji. Zastanówmy się teraz, dlaczego ważne jest, żeby anonimizacja była dobrej jakości.
Nieodwracalność
Fundamentem anonimizacji jest jej nieodwracalność. Na podstawie zanonimizowanych danych nigdy nie powinniśmy dociec, jak wyglądały dane oryginalne. Współpracownicy Clarka nie powinni odkryć jego prawdziwej tożsamości.
Kiedy zbiór danych poddajemy anonimizacji, to zazwyczaj zmianie ulega jedynie fragment danych. Musimy jednak zadbać o to, aby dane niezanonimizowane nie pozwoliły na odwrócenie procesu anonimizacji dla całego zbioru. W naszym przykładzie nie musielibyśmy zmieniać ulubionego koloru Supermana. Jeżeli jednak nie anonimizujemy jego pochodzenia, to z pewnością wzbudzimy sensację.
Realność
Istotną miarą jakościową anonimizacji jest też jej realność i to, jak dobrze odwzorowuje rzeczywistość. Jeżeli Superman i wszystkie inne osoby w zbiorze danych zostaną zanonimizowane w następujący sposób:
| Nazwa | X |
| Zawód | Y |
| Pochodzenie | Z |
to nie mamy wątpliwości, że proces jest nieodwracalny, jednak jego przydatność jest wątpliwa. Pan X nie wygląda na człowieka z krwi i kości, a charakter danych oryginalnych nie został zachowany. Długości nazw nie zostały zachowane, a same dane wyglądają na niewiarygodne i wszystkie osoby nazywają się tak samo. W przypadku systemów informatycznych tester wykorzystując takie dane miałby sporo problemów, nie byłby w stanie nawet rozróżnić osób.
Powtarzalność
Kolejną cechą dobrej anonimizacji jest jej powtarzalność. Anonimizując zbiór danych chcemy mieć pewność, że za każdym razem zbiór danych zostanie zanonimizowany w taki sam sposób. Chcemy, aby Superman zawsze stawał się Clarkiem Kentem, niezależnie czy jest to pierwsza, czy dziesiąta anonimizacja. Jest to szczególnie ważne z punktu widzenia Quality Assurance. Testerzy często tworzą przypadki testowe opierając się na konkretnych danych. Gdybyśmy je zmieniali za każdym razem, z pewnością praca testera byłaby trudniejsza!
Zintegrowane systemy
Dzisiejszy świat informatyki to systemy połączone. Prawie żadna aplikacja nie jest samotną wyspą. Systemy łączą się ze sobą, wymieniają danymi, korzystają ze swoich usług. Z tego też względu podchodząc do anonimizacji, musimy myśleć o procesie nie dla jednego, ale dla wielu systemów na raz. Wyzwaniem jest, aby zanonimizowane dane były spójne w całym ekosystemie. Oznacza to, że jeżeli Daily Planet (miejsce pracy Clarka) posiada system kadrowy oraz bloga, to w obu tych aplikacjach Superman stanie się Kentem.
Wydajność
Ostatnim z mojego punktu widzenia, kluczowym parametrem mającym wpływ na jakość anonimizacji jest wydajność. Systemy informatyczne przetwarzają olbrzymie zbiory danych liczonych w gigabajtach czy terabajtach. Anonimizacja takich baz danych może być czasochłonna w związku z czym musimy zapewnić nie tylko bezpieczeństwo, ale również szybkość procesu anonimizacji. Jedną z rzeczy, którą nauczył się Superman po przybyciu na Ziemię, jest to, że czas to pieniądz. To powiedzenie jest jeszcze bardziej prawdziwe w przypadku nowoczesnego IT.
Wszystkich zainteresowanych tematem retencji danych zapraszam do przeczytania kolejnego mojego artykułu, który planuję opublikować już niedługo.
Artur Żórawski, Founder&CTO Wizards